A-Mem:Agentic Memory for LLM Agents:记忆动态更新的 Agent 记忆系统
论文提出了一种名为 A-MEM 的适用于 Agent 的主动式记忆系统,通过构建笔记、链接生成、记忆进化三个环节,来尝试解决现有 LLM 代理记忆系统结构僵化、适应性不足的问题。
阅读更多论文提出了一种名为 A-MEM 的适用于 Agent 的主动式记忆系统,通过构建笔记、链接生成、记忆进化三个环节,来尝试解决现有 LLM 代理记忆系统结构僵化、适应性不足的问题。
阅读更多Mem0 是 Agent Memory 领域的经典作,针对现有 Agent 系统依赖上下文短期记忆,而对长期记忆优化不足的问题,设计了一种记忆组织与维护架构。同时一并提出基于知识图谱的 Mem0g。
阅读更多论文提出了LEGOMem,一个用于为Multi-Agent架构设计的模块化记忆系统。通过对多智能体系统中的各类角色设计模块化记忆,提高整个系统的持续协调与规划能力。
阅读更多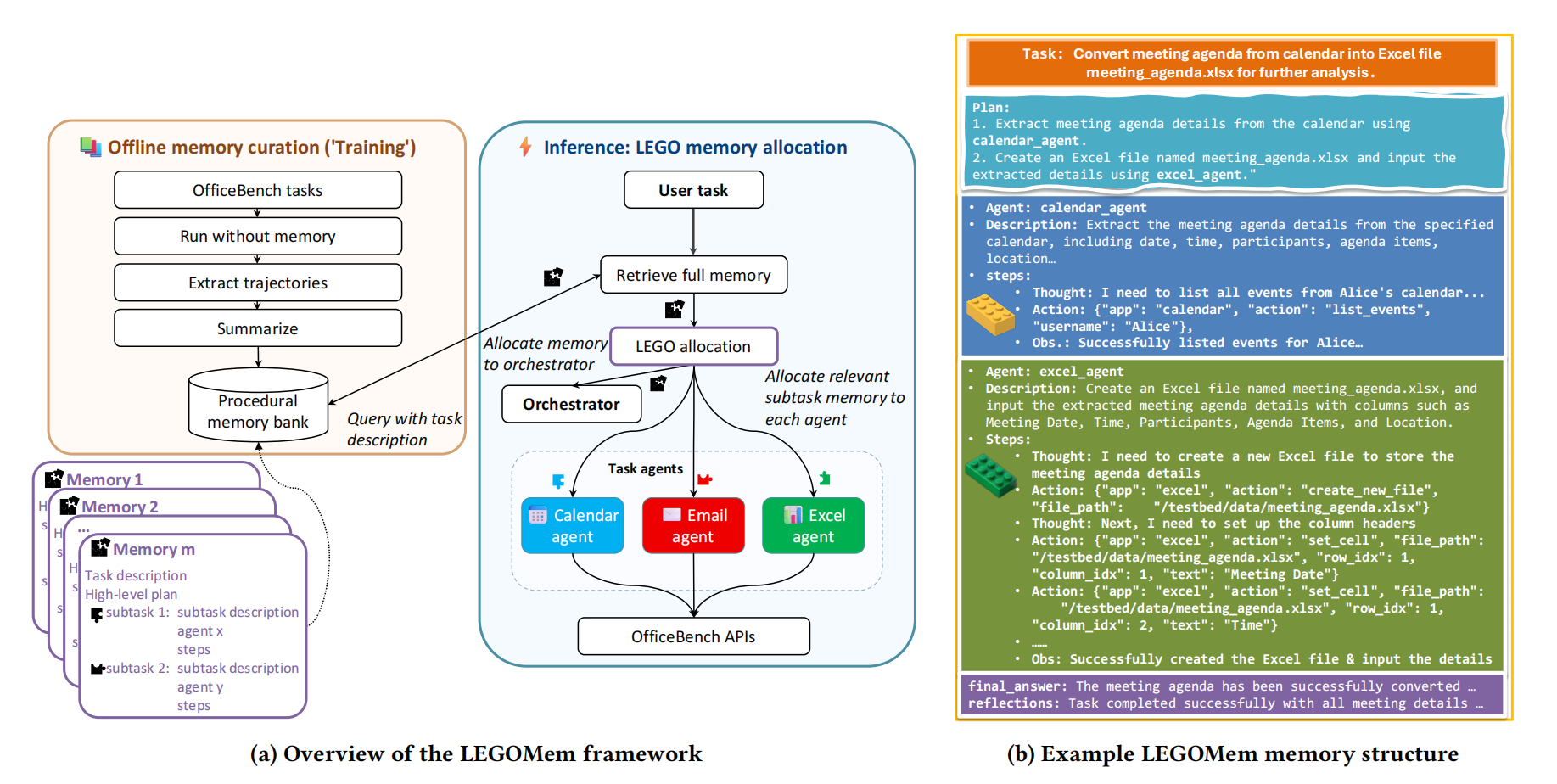 LEGOMem:Modular Procedural Memory for Multi-agent LLM Systems for Workflow Automation
LEGOMem:Modular Procedural Memory for Multi-agent LLM Systems for Workflow Automation
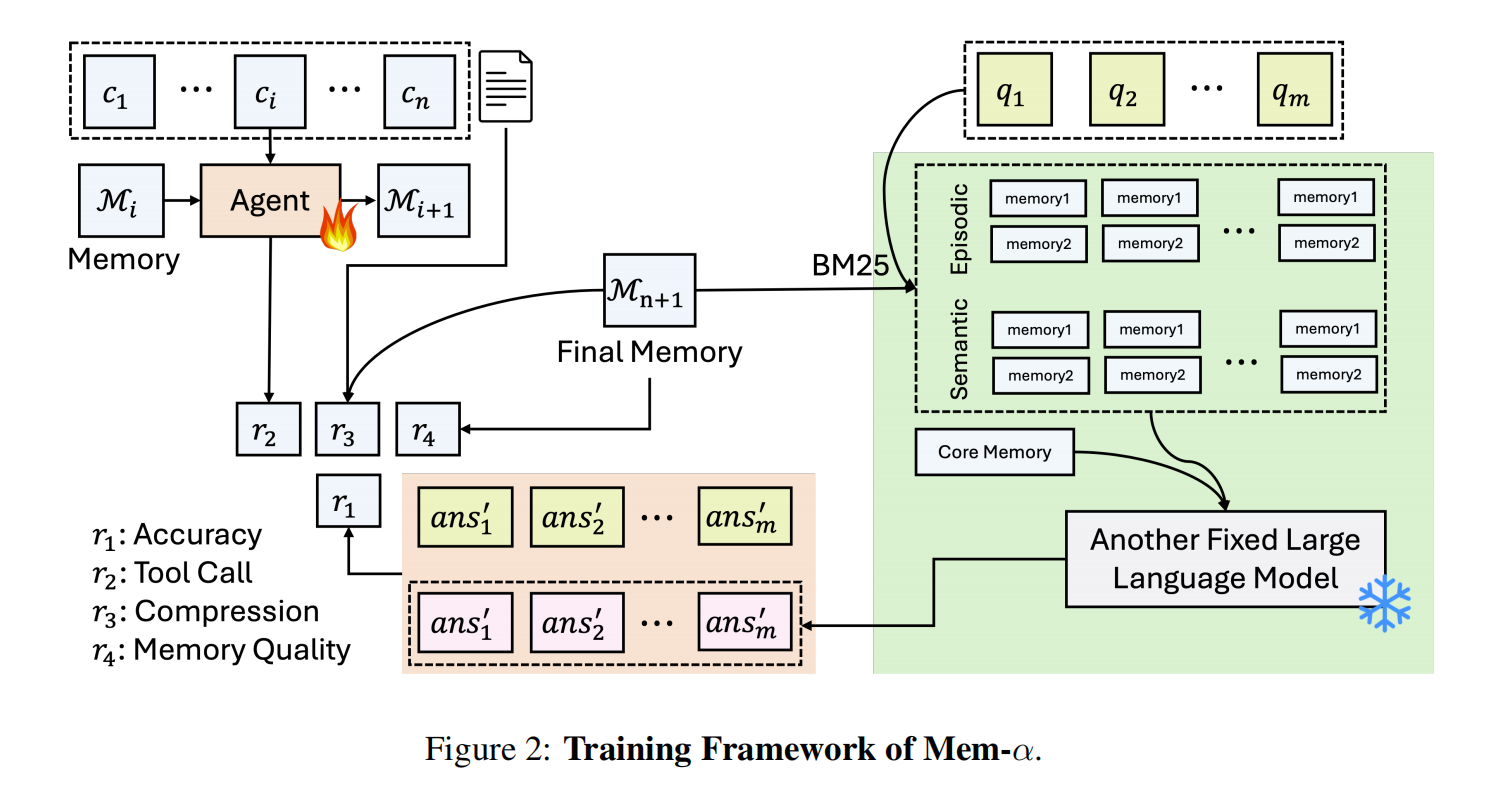 Mem-α: Learning Memory Construction via Reinforcement Learning
Mem-α: Learning Memory Construction via Reinforcement Learning
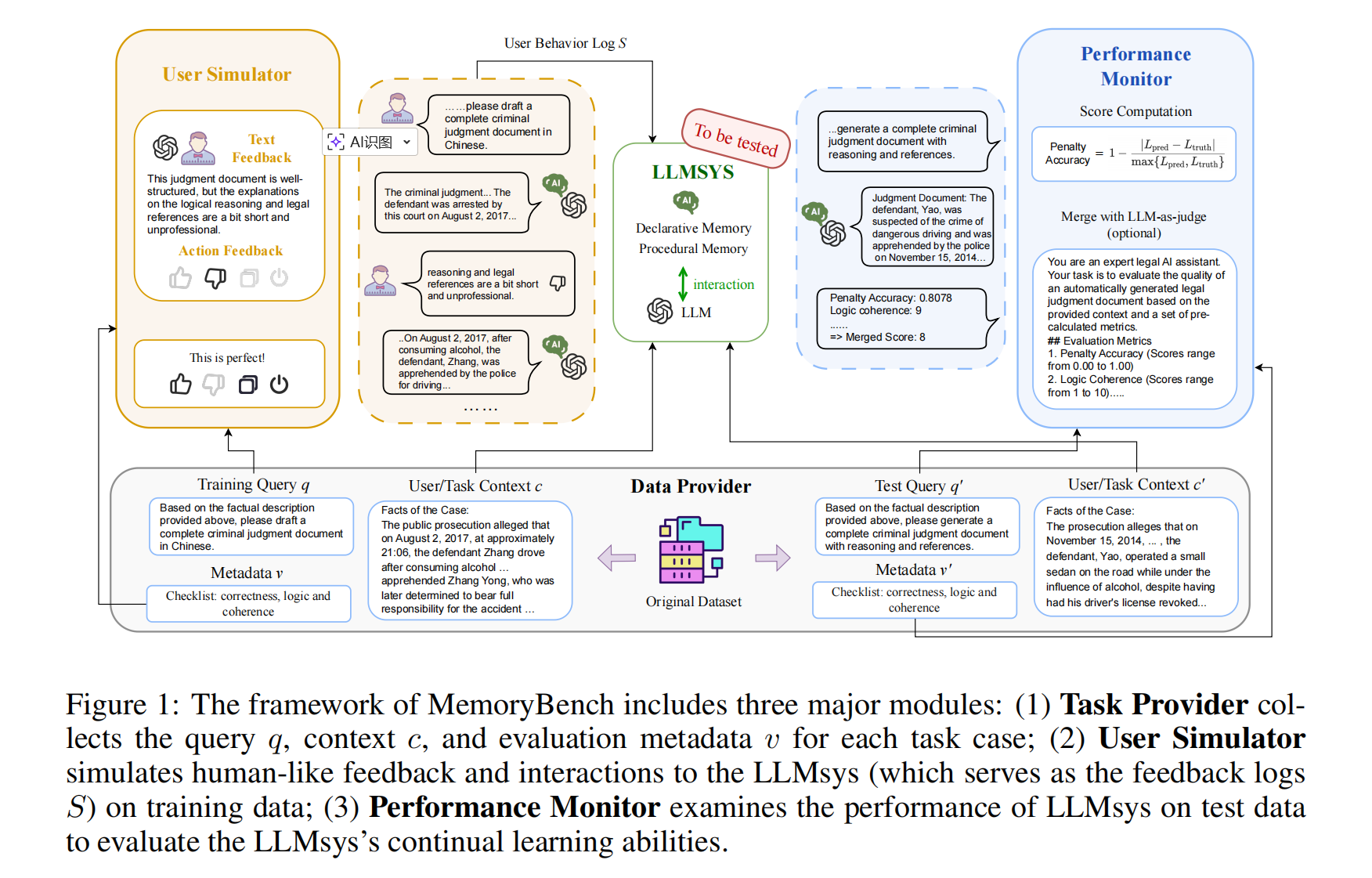 MemoryBench
MemoryBench
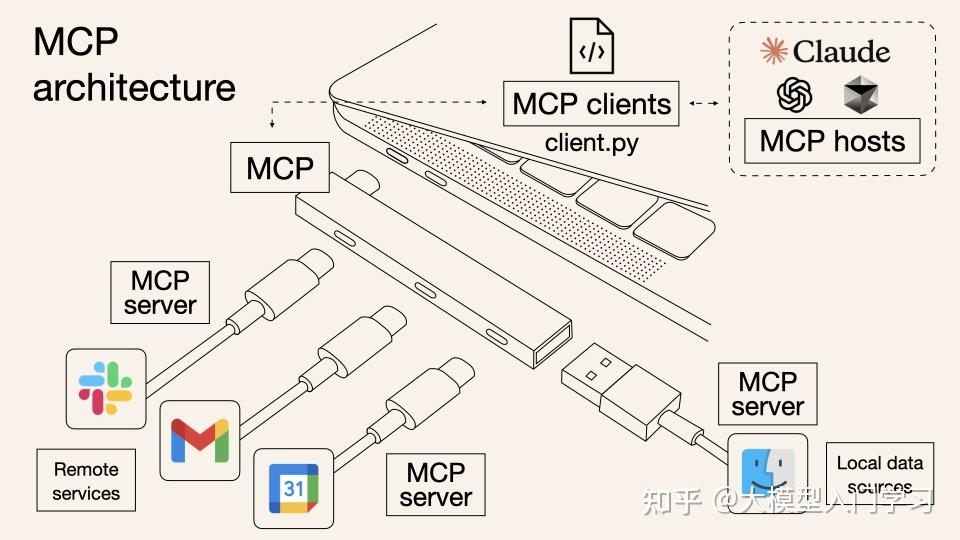 Function Calling and MCP
Function Calling and MCP
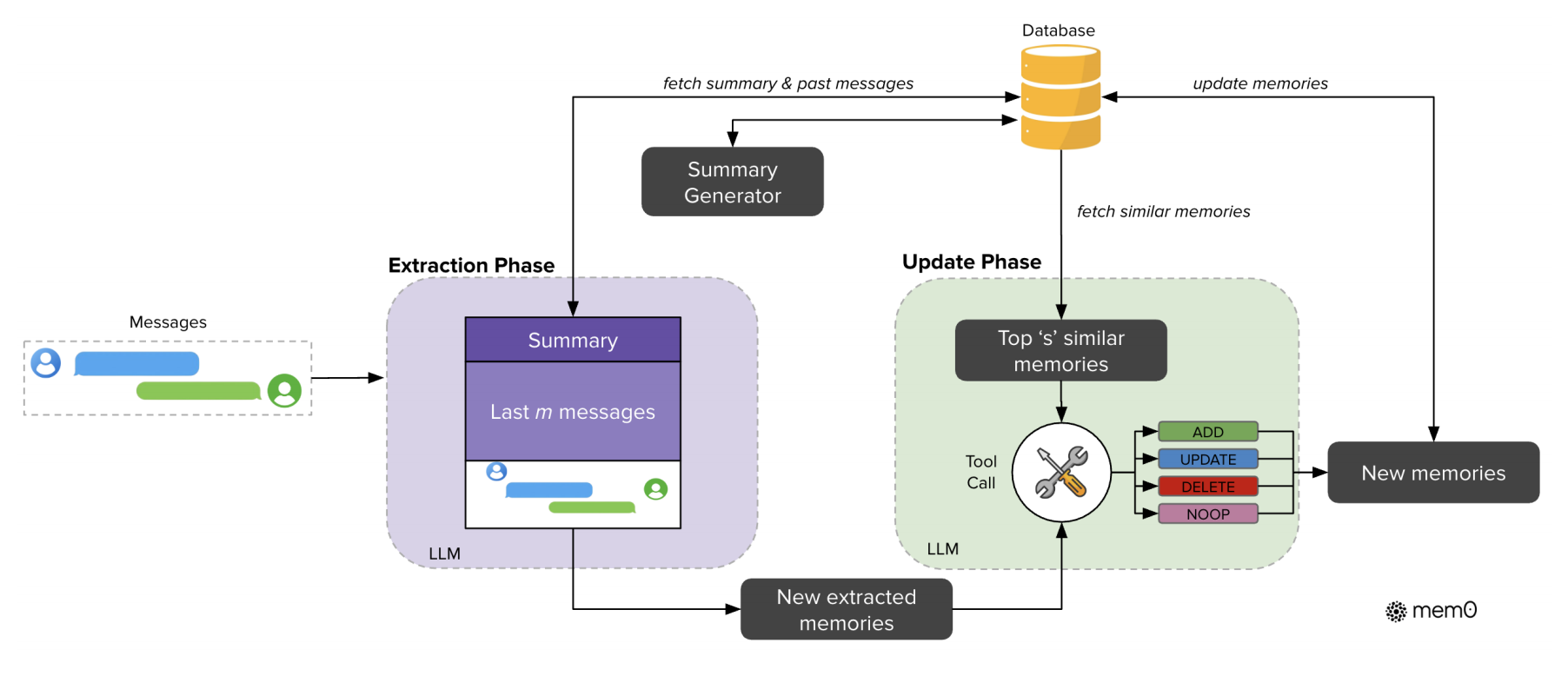 Mem0:Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0:Building Production-Ready AI Agents with Scalable Long-Term Memory
(1).png) Build an Agentic RAG System
Build an Agentic RAG System
 2025年(26届)四非CS保研经验帖
2025年(26届)四非CS保研经验帖
 Build Agent Syetem with Langgraph & DeepSeek
Build Agent Syetem with Langgraph & DeepSeek
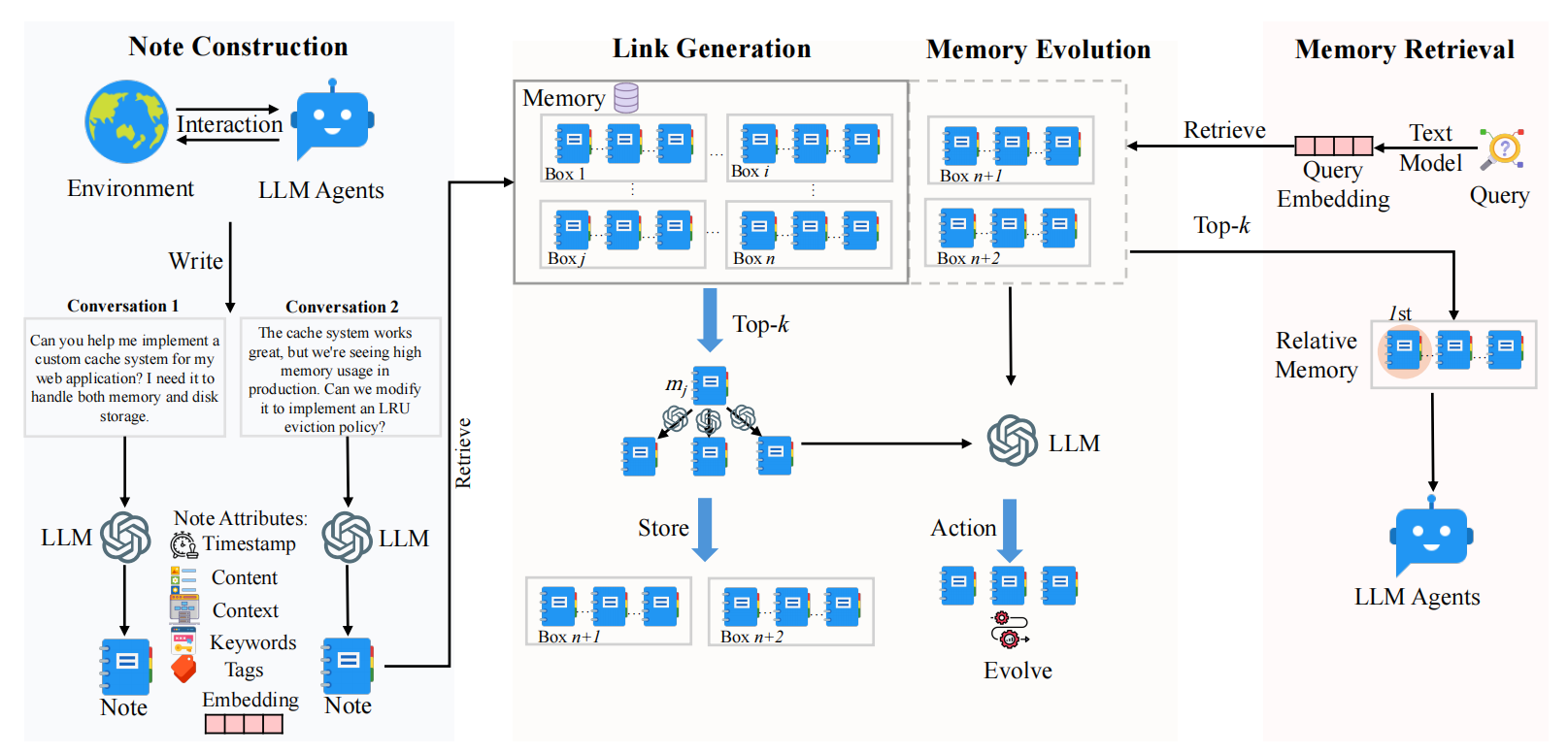 A-Mem:Agentic Memory for LLM Agents:记忆动态更新的 Agent 记忆系统
A-Mem:Agentic Memory for LLM Agents:记忆动态更新的 Agent 记忆系统
 在DeepSeek-R1-1.5b模型上做一个简单的lora微调
在DeepSeek-R1-1.5b模型上做一个简单的lora微调
 手写一个lora微调算法
手写一个lora微调算法
 DeepSeekMoE:我们需要更多Experts!
DeepSeekMoE:我们需要更多Experts!