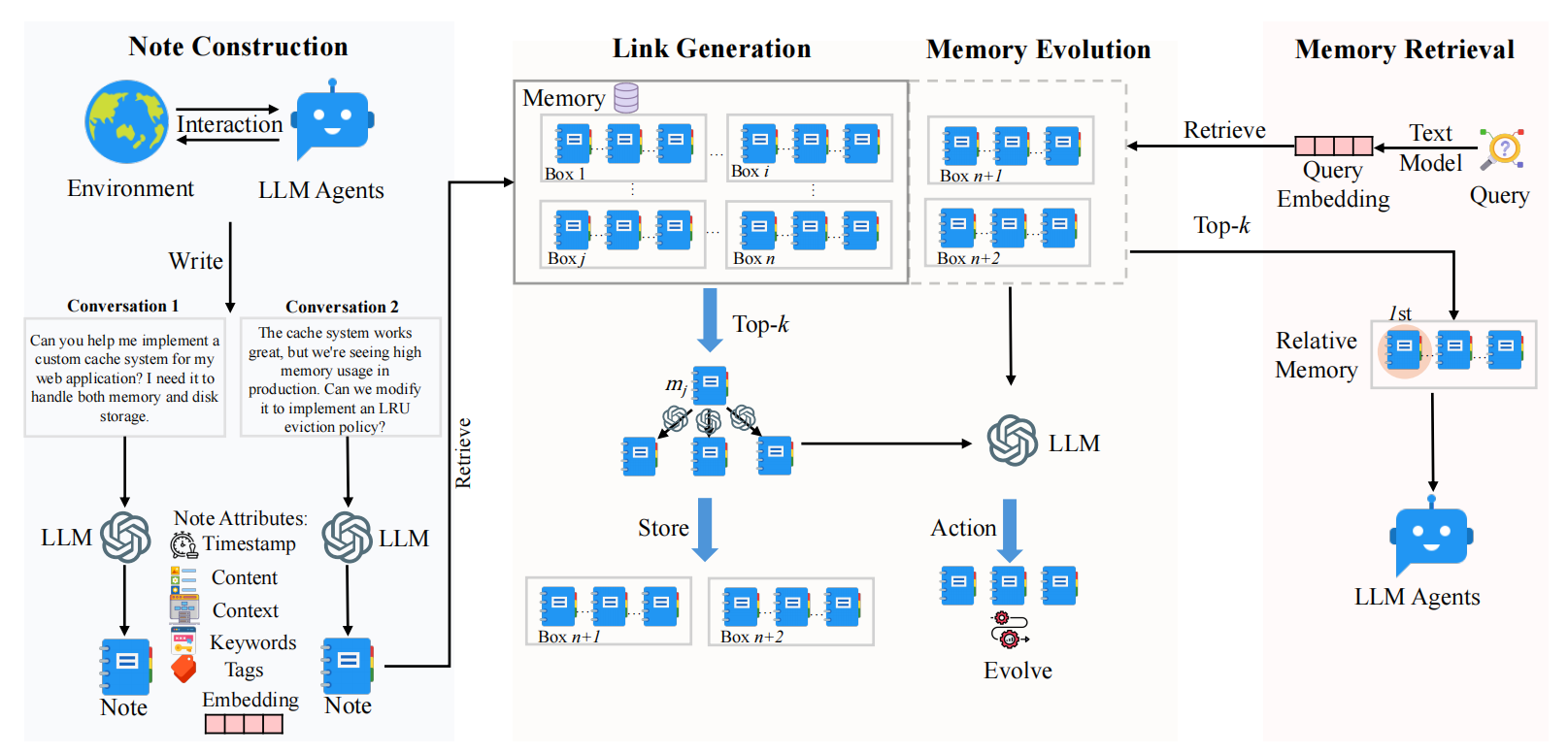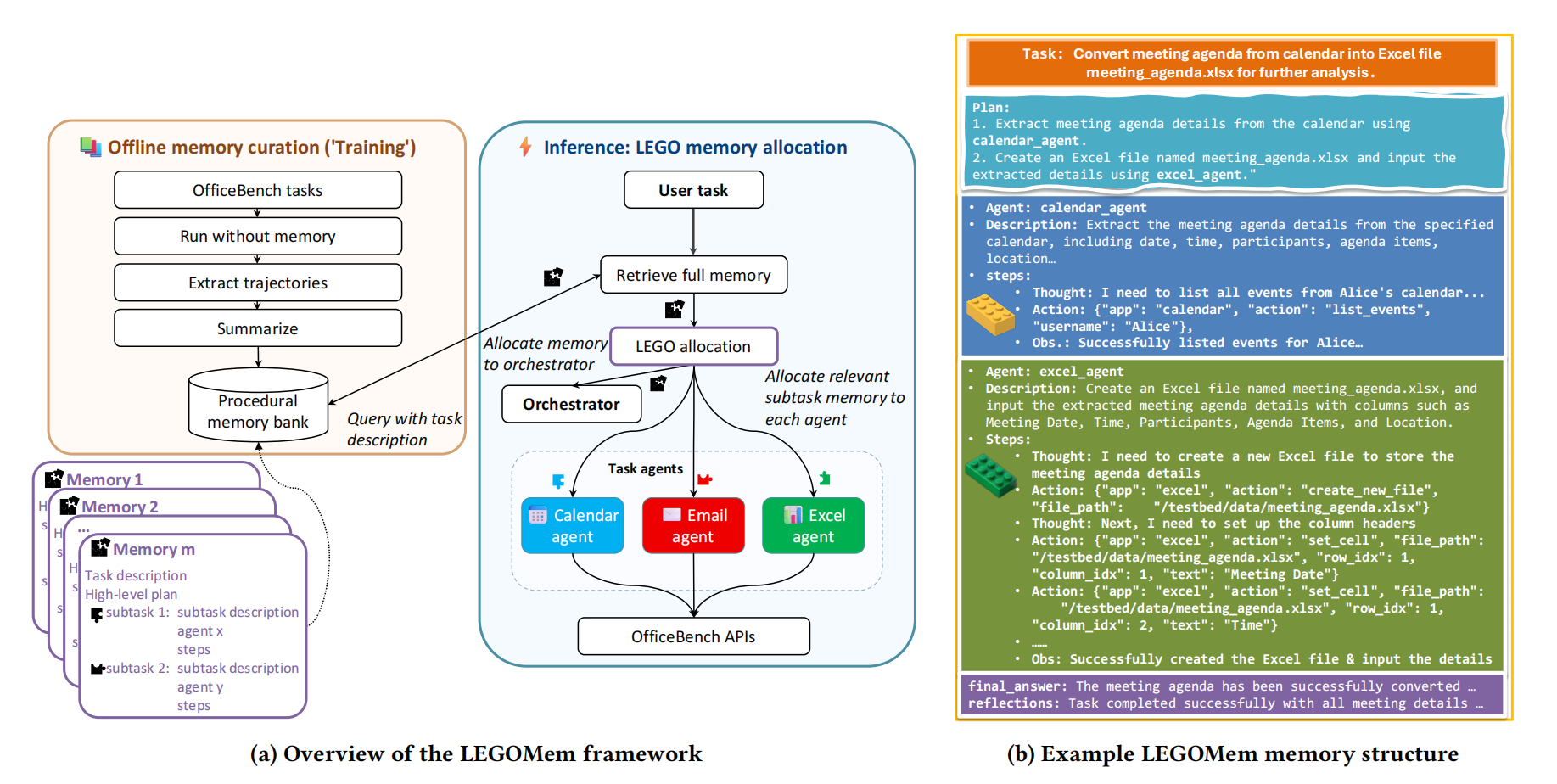
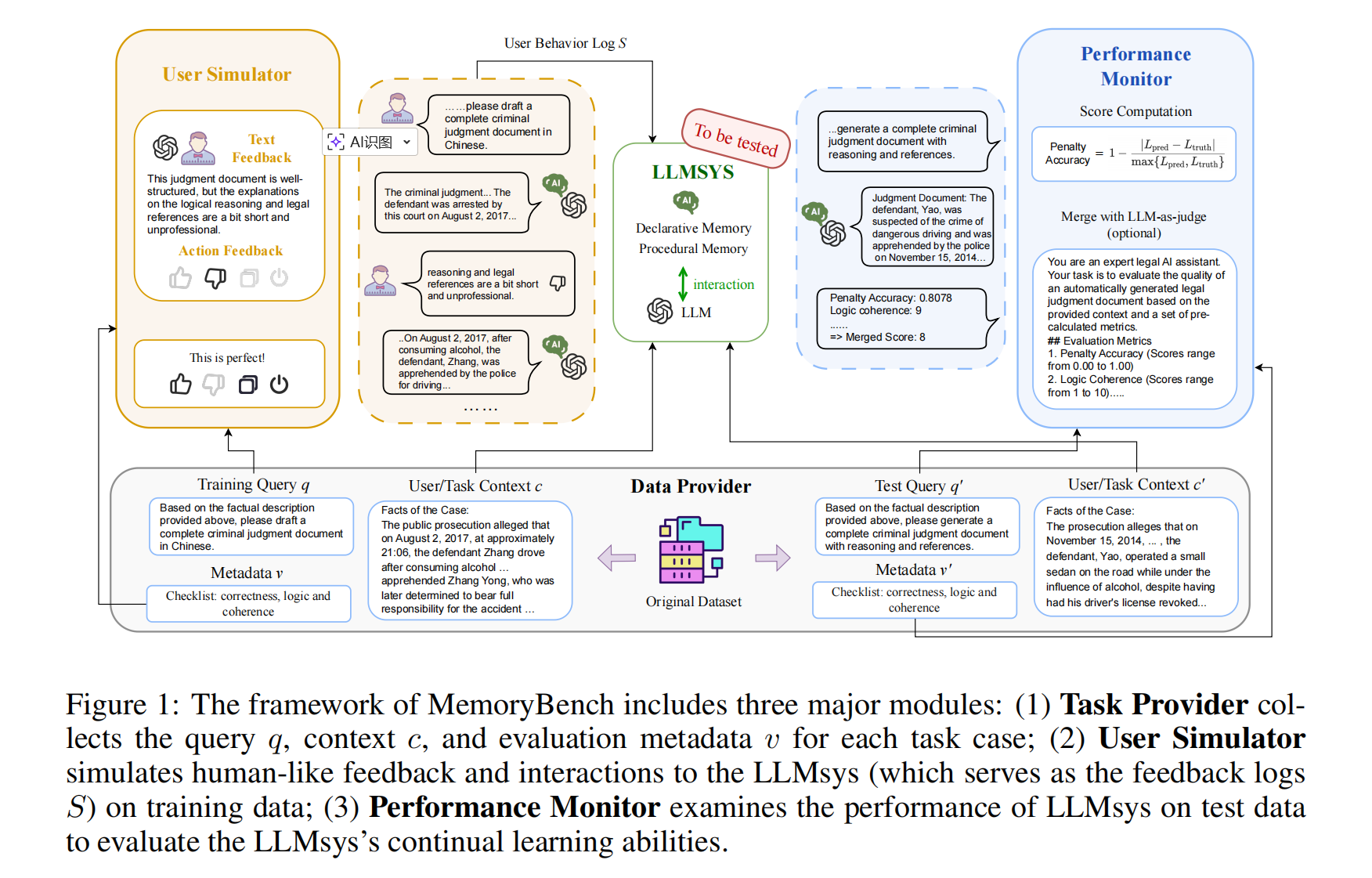
论文提出了LEGOMem,一个用于为Multi-Agent架构设计的模块化记忆系统。通过对多智能体系统中的各类角色设计模块化记忆,提高整个系统的持续协调与规划能力。
2025-11-22
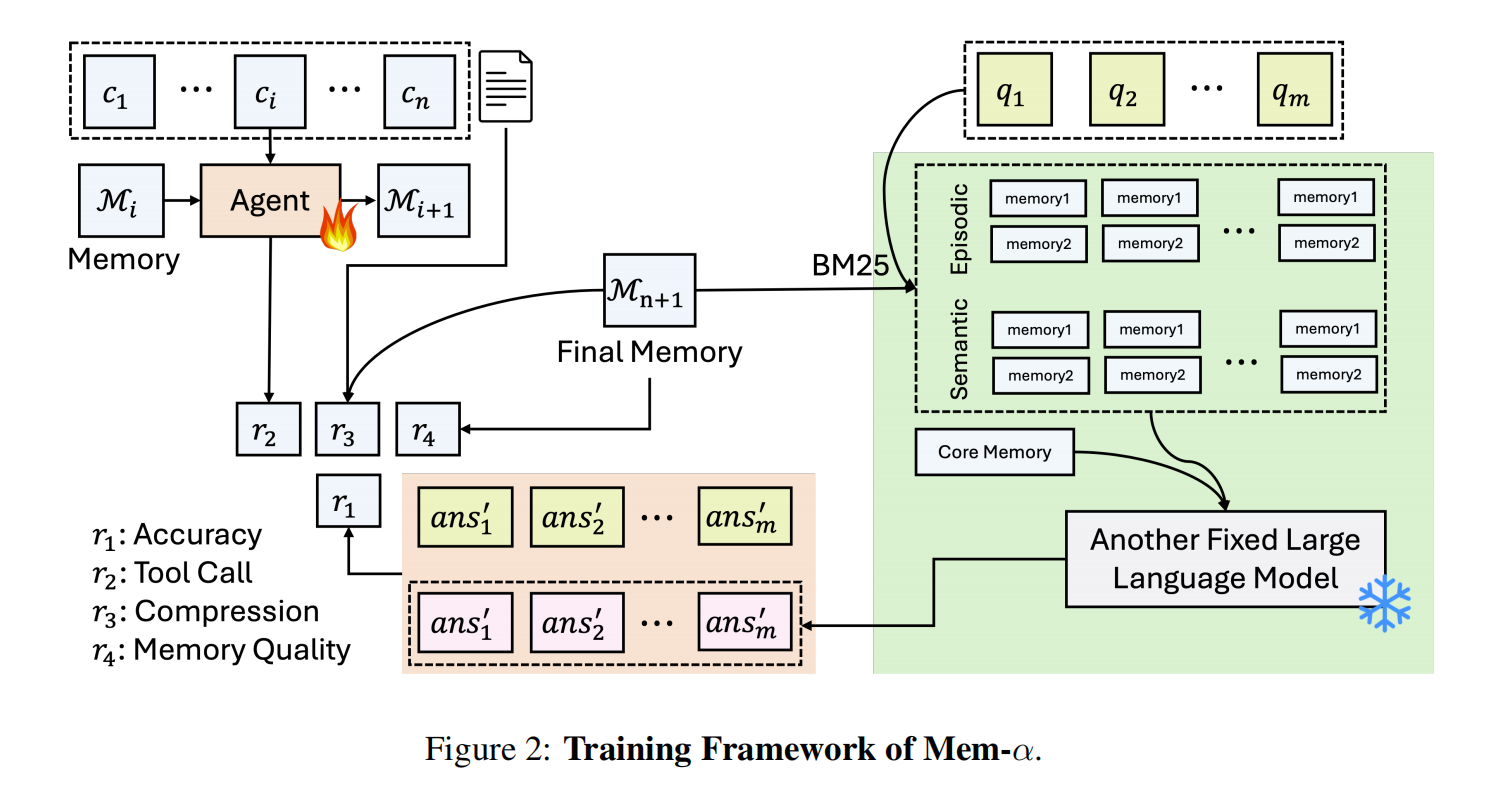
(1).png)