A-Mem:Agentic Memory for LLM Agents
原文链接:https://arxiv.org/abs/2502.12110
论文主要提出了一种名为 A-MEM 的适用于 Agent 的主动式记忆系统,来尝试解决现有 LLM 代理记忆系统结构僵化、适应性不足的问题。
Background & Motivation
我们知道,Agent 的记忆一般分为短期记忆和长期记忆,短期记忆可通过维护上下文窗口提供,而长期记忆往往需要维护一个记忆存储库,在每次交互时对存储库里的记忆进行写入与调用。

传统记忆系统一般会预定义存储结构、存储点、记忆关联。 例如,记忆存储格式固定为数据库 Table 结构或 Json 模版;硬性规定在特定对话轮次或步骤写入记忆;记忆之间彼此孤立或硬性定义其关联。这种记忆系统交互是线性且固定的,缺乏自主性,体现出如下缺陷:
- 灵活性差: 在更复杂开放的一些场景下,预定义的知识模式可能不能很好地匹配现有需求。
- 长期交互效果不佳: 记忆孤立且静态,新记忆难以与旧记忆产生联系,也无法更新记忆,模型难以在长期对话中维持深入推理。
- 知识组织僵化: 如论文所述,当代理学习到一个新数学解法时,无法主动创建新的组织模式,或发现新联系。
因此,A-Mem 针对上述问题改进,灵感基于 Zettelkasten 方法(使用原子笔记和灵活的链接机制,可以创建相互连接的信息网络),设计了一个具备自主性(能够自主建立记忆联系并更新记忆)的记忆系统。
Zettelkasten 方法是一种知识管理系统,由德国社会学家 Niklas Luhmann 提出。它通过创建相互连接的笔记网络来组织知识,每张笔记(Zettel)包含一个独立的想法,并通过链接与其他相关的笔记连接起来。
Related Works Comparison
| Method | Core Mechanism | Limit |
|---|---|---|
| MemGPT | 类 OS 系统的内存分层 | 固定大小的上下文窗口 |
| MemoryBank | 基于遗忘曲线进行动态更新 | 缺乏跨记忆的语义关联 |
| Agentic RAG | 系统自主检索增强 | 知识库静态,不可更新 |
| A-MEM | 动态链接 + 自主进化 | 上下文表征可能不够丰富 |
Method
A-Mem的核心是一个动态、自演进的内存网络。每当代理有一次新交互,系统会执行三步操作:
- 笔记构建:将原始交互转化为结构化的记忆笔记;
- 链接生成:自动寻找与已有记忆的关联并建立链接;
- 记忆进化:根据新记忆更新相关旧记忆的上下文或标签。
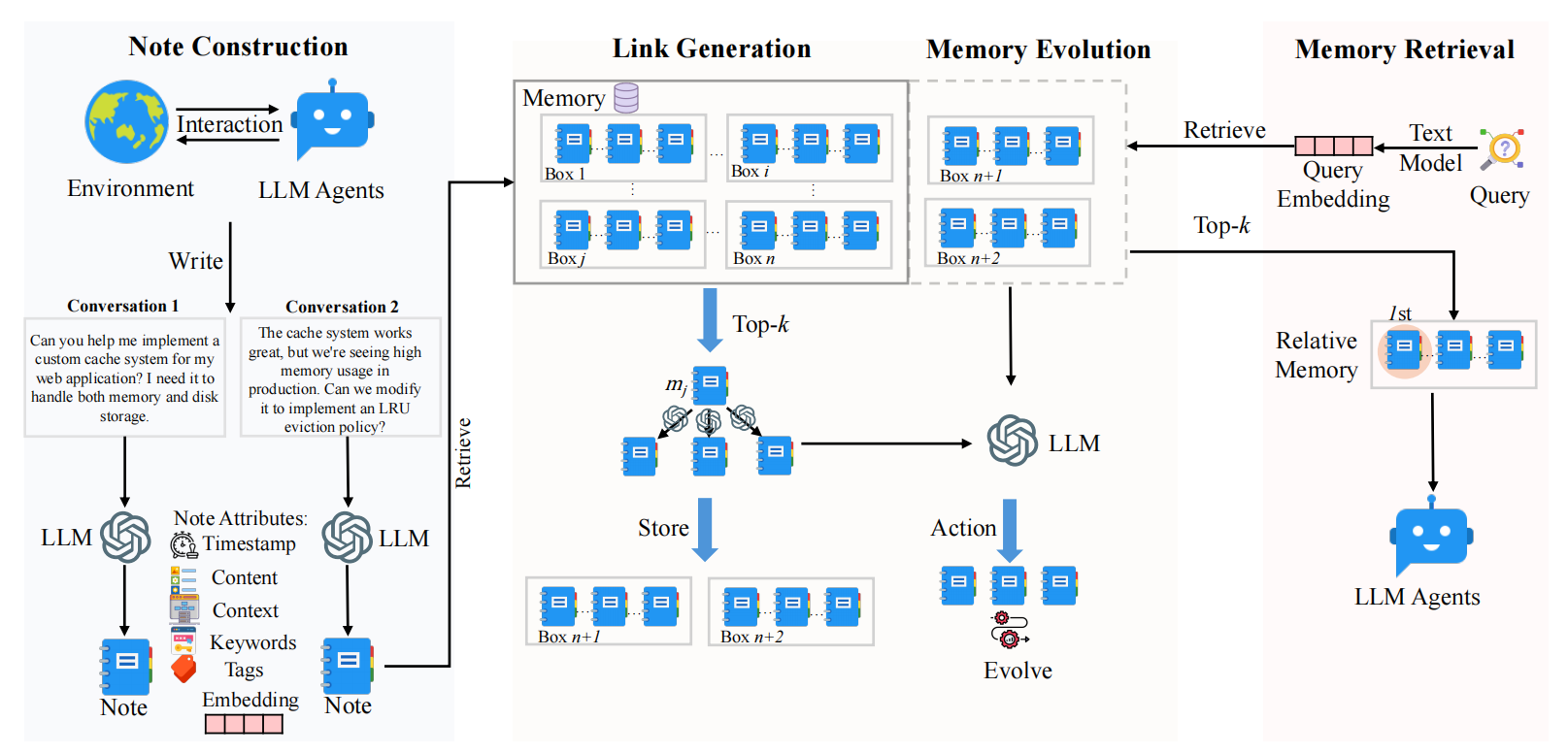
原子笔记构建
对于每一个记忆单元可以表示为:$m_{i}={c_{i}, t_{i}, K_{i}, G_{i}, X_{i}, e_{i}, L_{i}}$
- $m_{i}$ :第 i 个记忆笔记。
- $c_{i}$ :原始交互内容(content),例如对话文本、观察到的事件等。
- $t_{i}$ :时间戳(timestamp),记录记忆发生的时间。
- $K_{i}$ :LLM 生成的关键词(keywords),用于捕捉记忆的关键概念。
- $G_{i}$ :LLM 生成的标签(tags),用于对记忆进行分类。
- $X_{i}$ :LLM 生成的上下文描述(contextual description),提供丰富的语义理解。包含隐含语义,如「该解法与拓扑学存在潜在联系」。
- $e_{i}$ : 嵌入向量(embedding),用于相似度计算和检索。
- $L_{i}$ :链接记忆集合(linked memories),包含与当前记忆相关的其他记忆。
这种做法有什么好处呢?
传统方法的记忆结构(如数据库表或JSON字段)是固定的,并且内容通常直接来自原始交互数据(例如,直接存储用户消息和模型响应),缺乏语义增强。存储什么、如何存储完全由预定义规则决定。
而 A-Mem 的每个记忆笔记中的关键词(Ki)、标签(Gi)和上下文描述(Xi)都是由LLM在每次交互后动态生成的。这意味着即使结构模板固定,但其内容是根据当前交互的语义灵活生成的,从而适应不同任务和语境。
链接生成
首先通过余弦相似度初步筛选 Top-K 候选记忆单元:$[ s_{n,j} = \frac{e_n \cdot e_j}{|e_n||e_j|} ]$
接下来,借助 LLM 来分析候选记忆的深层关系,并建立连接:
$L_{i} ← LLM(m_{n}||M_{near}^{n}||P_{s2})$
这里 $P_{s2}$ 是预定义的提示词模版,通过 LLM 来生成链接关联。
记忆更新
新记忆 $m_{n}$ 的进入会触发历史记忆的更新,更新公式为:
$m_{j}^{*} ← LLM(m_{n} || M_{near}^{n} \ m_{j} || m_{j} || P_{s3})$
例如,当学习「量子退火」后,系统自动将历史记忆「模拟退火算法」的标签更新为「优化算法→量子计算」。
Experiment & Results
- 数据集:LoCoMo 数据集,包含长时间的对话,适合评估模型处理长程依赖关系和保持一致性的能力。
- 评估指标:F1 score、BLEU-1、ROUGE-L、ROUGE-2、METEOR、SBERT Similarity。
- 基线模型:LoCoMo、ReadAgent、MemoryBank、MemGPT。
实验结果:
在非 GPT 基础模型上,A-MEM 始终优于所有基线模型。
在 GPT-4-mini 上,A-MEM 的 F1 得分达到 45.85%,远超 MemGPT 的 25.52%
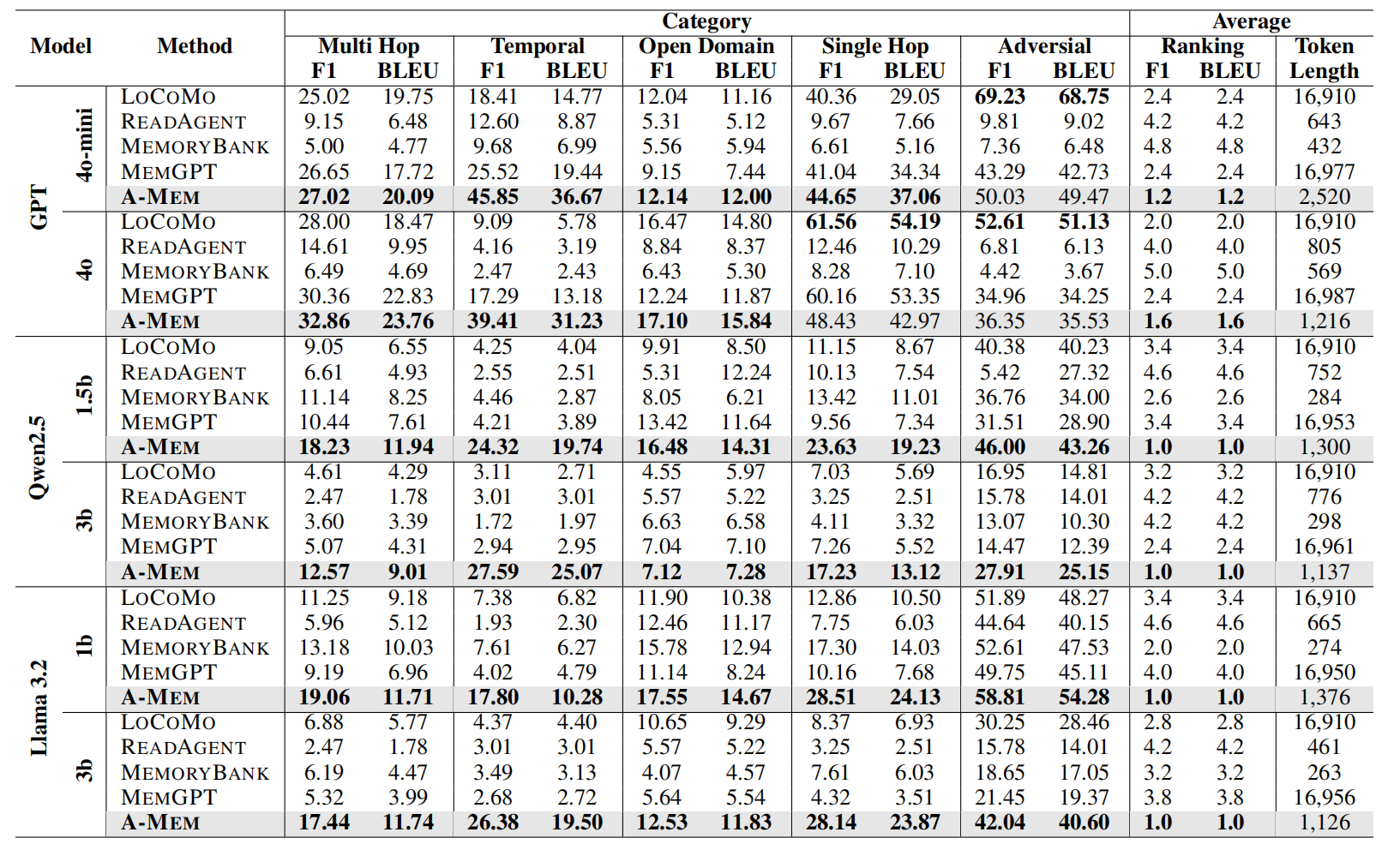
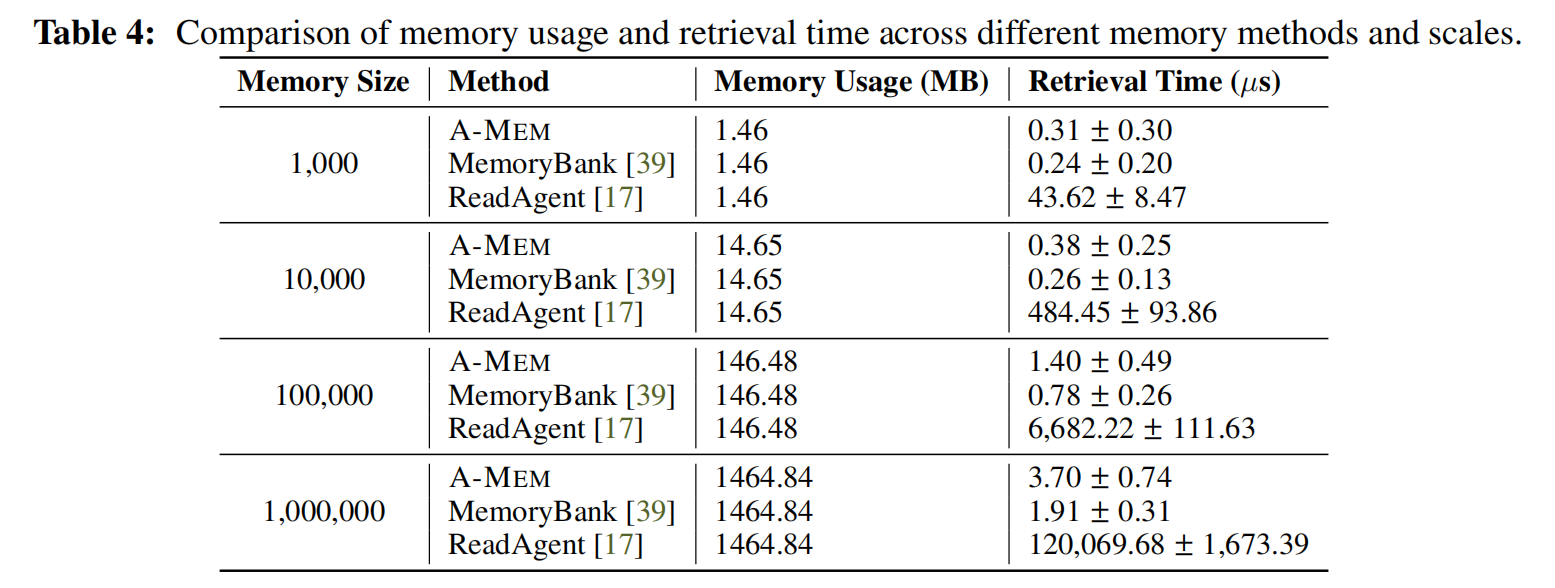
效率优势: A-MEM 在实现这些改进的同时,与 LoCoMo 和 MemGPT 相比,token 长度要求显著降低(约 1,200-2,500 个 token,而 LoCoMo 和 MemGPT 为 16,900 个 token)。
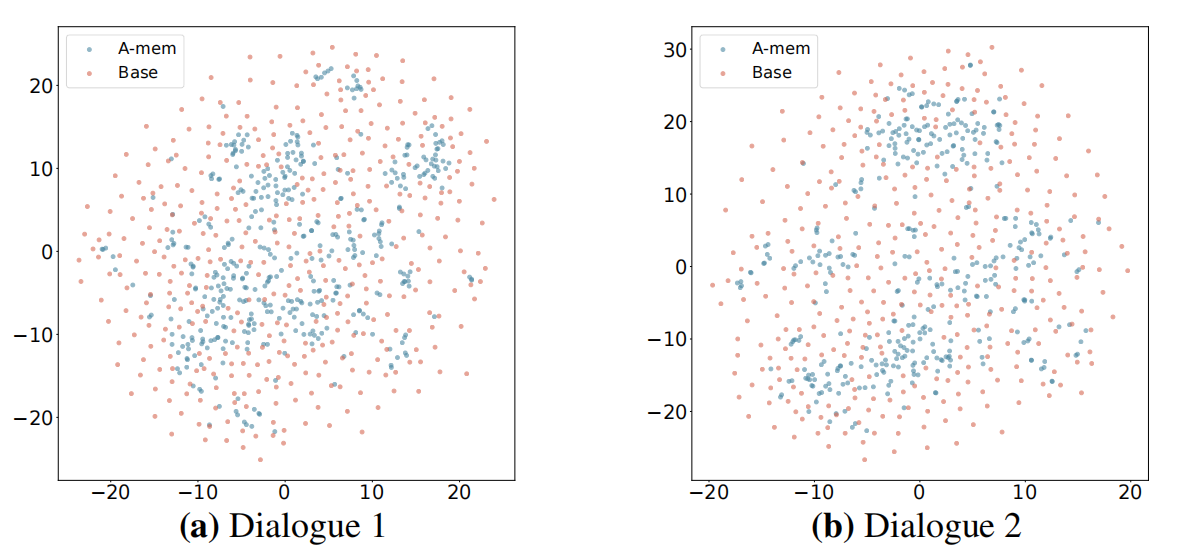
可视化证据: t-SNE 可视化表明,与基线系统相比,A-MEM 具有更连贯的聚类模式,验证了其记忆组织方法的有效性。
消融实验:链接生成(LG)和记忆演化(ME)模块对 A-MEM 的性能至关重要。
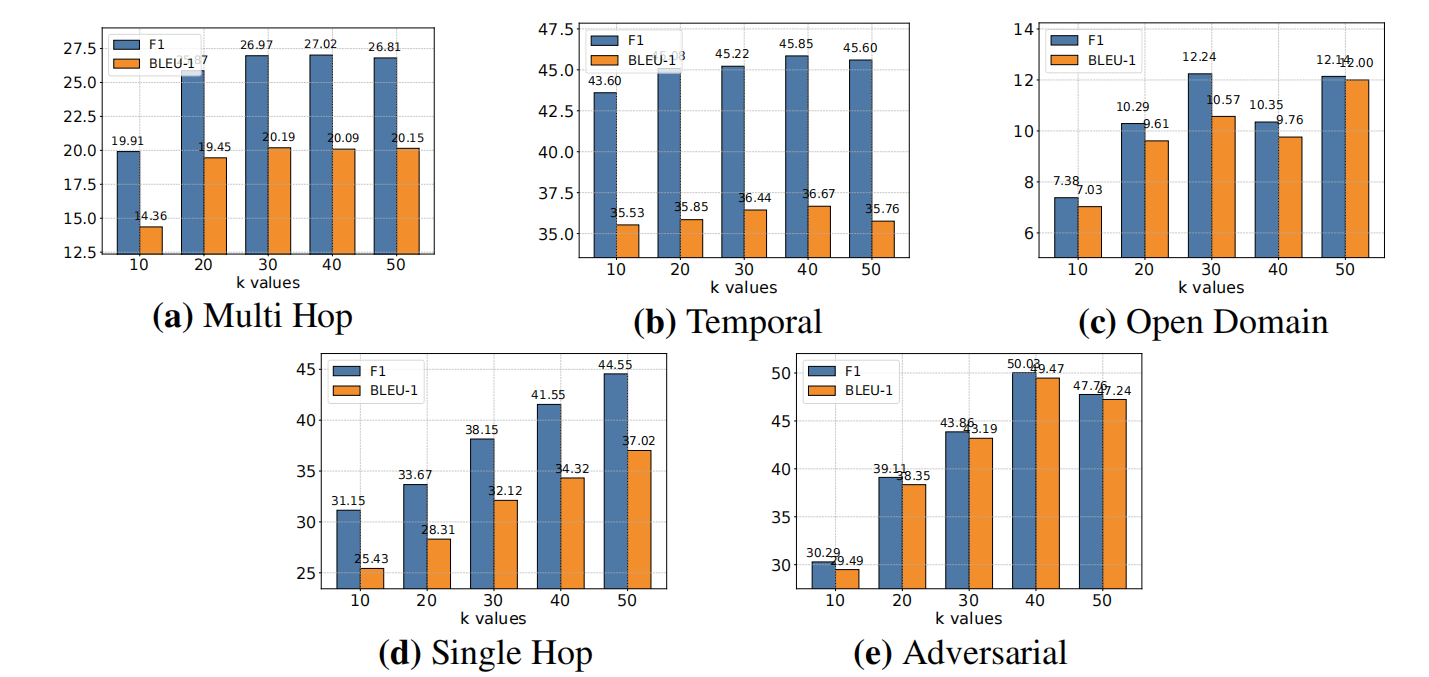
超参数分析:适中的 k 值(检索记忆的数量)在上下文丰富性和信息处理效率之间取得了最佳平衡。k 值持续增大,也会伴随效果下降。
My Thoughts
A-Mem 的方法本身并不难理解,但其方法很有效。通过 A-Mem 得到的惊艳效果,可以看到仅仅基于传统 RAG 的方法引入外部数据库来存储记忆是远远不够的。可以从中提炼出关于 Agent 长期记忆的几个要点:
- 记忆之间需要建立相互连接的关系(并非人为固定定义);
- 模型记忆需要伴随着演化更新,并非一成不变,类似模型知识编辑;
- A-Mem 取得的效果大概率依赖于 LLM 生成的对记忆的上下文描述;
论文中提到的 Future Works 包括引入多模态信息、解决不同大模型上下文生成区别等,不过感觉都不是一些关键点。
读完之后有几个初步的思考点,大概是这些:
首先,A-Mem 并未引入遗忘机制,记忆库会无限膨胀。当记忆库很庞大时,通过向量相似度初筛可能就会引入记忆污染等等问题。能否在其大体机制上稍加修改,引入记忆遗忘与压缩机制,在更大规模的对话数据集上实验验证效果?
个人想法是,人类对于记忆的“遗忘”与“调用”过程更像是对记忆的一个置信度评估,像 MemGPT 那样基于 OS 的记忆管理思路那样,能否对记忆施加一个“置信度”参数,随模型链接记忆的时间次数而衰减,或设定一个置信度的传播与更新机制,在链接时优先考虑高置信度的相关记忆,并优先忘却低置信度的相关记忆?
另外,A-Mem 给出的几个启发能否也在参数化记忆上做一些尝试呢?现有的参数化记忆更新方法大多通过模型微调、增加模型 memory block 等实现。记忆之间建立相互连接的关系通常也通过知识图谱等方式添加到模型网络中去。
一般当前的方法都是仅单独专注于非参数化记忆优化、参数化记忆优化本身,很少有把两者结合起来做的工作。之前也读过几篇模型知识编辑相关的论文,能否把长期记忆更新和模型编辑相结合,在模型参数化记忆上也去做一个更新改动呢?