手搓Transformer:Multi-Attention
《Attention Is All You Need》里的Transformer架构

1. Self-Attention
自注意力的作用:随着模型处理输入序列的每个单词,自注意力会关注整个输入序列的所有单词,帮助模型对本单词更好地进行编码。在处理过程中,自注意力机制会将对所有相关单词的理解融入到我们正在处理的单词中。更具体的功能如下:
序列建模:自注意力可以用于序列数据(例如文本、时间序列、音频等)的建模。它可以捕捉序列中不同位置的依赖关系,从而更好地理解上下文。这对于机器翻译、文本生成、情感分析等任务非常有用。
并行计算:自注意力可以并行计算,这意味着可以有效地在现代硬件上进行加速。相比于RNN和CNN等序列模型,它更容易在GPU和TPU等硬件上进行高效的训练和推理。(因为在自注意力中可以并行的计算得分)
长距离依赖捕捉:传统的循环神经网络(RNN)在处理长序列时可能面临梯度消失或梯度爆炸的问题。自注意力可以更好地处理长距离依赖关系,因为它不需要按顺序处理输入序列。
自注意力的计算:
Self-Attention 是通过输入本身的序列作为 Q 和 K 计算注意力分数的。从每个编码器的输入向量(每个单词的词向量,即Embedding,可以是任意形式的词向量,比如说word2vec,GloVe,one-hot编码)中生成三个向量,即查询向量、键向量和一个值向量。(这三个向量是通过词嵌入与三个权重矩阵相乘后创建出来的)
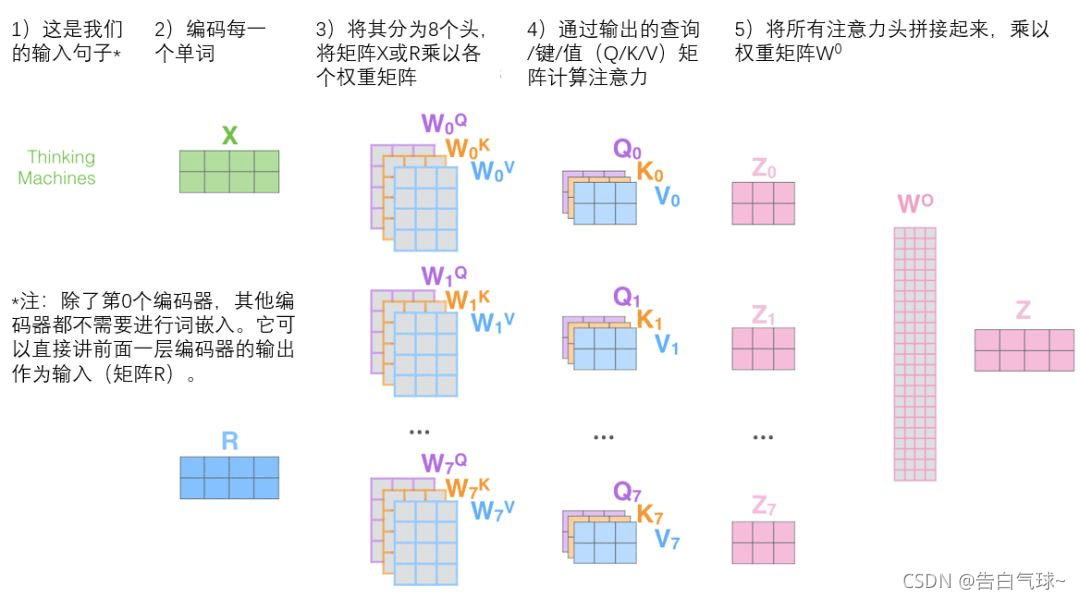
参考 CSDN @告白气球 的这张图:

经过上一节 Embedding 层后的嵌入输出维度为 (batch_size, seq_len, d_model),通过 nn.Linear 线性变换为 k, q, v 向量。然后经过注意力分数计算的公式即可得到注意力 score:q 和 k 先相乘,得到 (batch_size, num_heads, seq_len, seq_len) 的score矩阵,矩阵表示序列中每个位置对所有其他位置的注意力权重;softmax 之后与 v 相乘,score 的形状变为 **[batch_size, num_heads, seq_len, n_d]**。
2. Multi-Head
self-attention只是使用了一组 WQ、WK、WV 来进行变换得到查询、键、值矩阵,而 Multi-Head Attention 使用多组WQ,WK,WV得到多组查询、键、值矩阵,然后每组分别计算得到一个 Z 矩阵。
将所有注意力头 Z 矩阵拼接起来,得到的就是合并了所有头的注意力信息。展平 num_heads 维度,得到 [batch_size, seq_len, d_model] 形状的 score。
最后用一个附加的权重矩阵 W^O 乘以 score,将展平的score通过线性层投影回 d_model 维度,并加上偏置。这个线性变换将合并后的表示投影到一个更有意义的空间。
总结整个流程就是:
最后附上带有详细注释的代码,流程应该很清楚:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import torch.nn.functional as F
import numpy as np
import random
import math
from torch import Tensor
# batch_size, seq_len, d_model
x = torch.rand(128, 32, 512)
class MultiHeadAttention(nn.Module):
def __init__(self, d_model: int, num_heads: int):
super(MultiHeadAttention, self).__init__()
self.d_model = d_model
self.num_heads = num_heads
# 线性层的权重矩阵形状为(d_model, d_model)
# 输入的形状为(batch_size, seq_len, d_model),线性变换(wx+b)后得到k,q,v
# 不过一般新向量在维度上往往比词嵌入向量更低
# W_q:学习"我应该关注什么"的特征表示
# W_k:学习"我能提供什么信息"的特征表示
# W_v:学习"我的实际内容是什么"的特征表示
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_o = nn.Linear(d_model, d_model)
self.softmax = nn.Softmax(dim=-1)
def forward(self, q, k, v, mask=None):
batch_size, seq_len, d_model = q.size()
n_d = self.d_model // self.num_heads
# 将输入向量x线性变换为q,k,v
q,k,v = self.w_q(q), self.w_k(k), self.w_v(v)
# 这里通过view操作将d_model维度拆分为num_heads个头,每个头的大小为n_d
# 然后通过permute操作将头维度移到前面,变成(batch_size, num_heads, seq_len, n_d)
# 目的:1.减少计算量,并行计算;2.每个头可以关注不同特征子空间
q = q.view(batch_size, seq_len, self.num_heads, n_d).permute(0, 2, 1, 3)
k = k.view(batch_size, seq_len, self.num_heads, n_d).permute(0, 2, 1, 3)
v = v.view(batch_size, seq_len, self.num_heads, n_d).permute(0, 2, 1, 3)
# 这里k.transpose(2,3)将k的维度从(batch_size, num_heads, seq_len, n_d)变为(batch_size, num_heads, n_d, seq_len)
# 这样q和k相乘后,得到(batch_size, num_heads, seq_len, seq_len)的score矩阵
# 矩阵表示序列中每个位置对所有其他位置的注意力权重
# score[b, h, i, j] 表示在批次 b 的第 h 个头中,位置 i 对位置 j 的注意力分数
score = q@k.transpose(2,3) / math.sqrt(n_d)
# 将 mask 中值为0的位置在 score 中填充为一个很大的负数 -1e9
# 在编码器自注意力中,通常不使用掩码,允许每个位置关注所有位置
# 在解码器自注意力中,使用掩码确保每个位置只能关注其前面的位置
# 在填充掩码中,用于忽略填充标记的影响
if mask is not None:
score = score.masked_fill(mask == 0, -1e9)
# self.softmax(score) 将注意力分数转换为概率分布(每行和为1)
# score 的形状变为 [batch_size, num_heads, seq_len, n_d]
score = self.softmax(score)@v
# 将 score 的维度转换为 [batch_size, seq_len, num_heads, n_d]
# 然后展平 num_heads 维度,得到 [batch_size, seq_len, d_model]
score = score.permute(0,2,1,3).contiguous().view(batch_size, seq_len, d_model)
# 将展平的score通过线性层投影回d_model维度,并加上偏置
# 这个线性变换将合并后的表示投影到一个更有意义的空间
out = self.w_o(score)
return out



