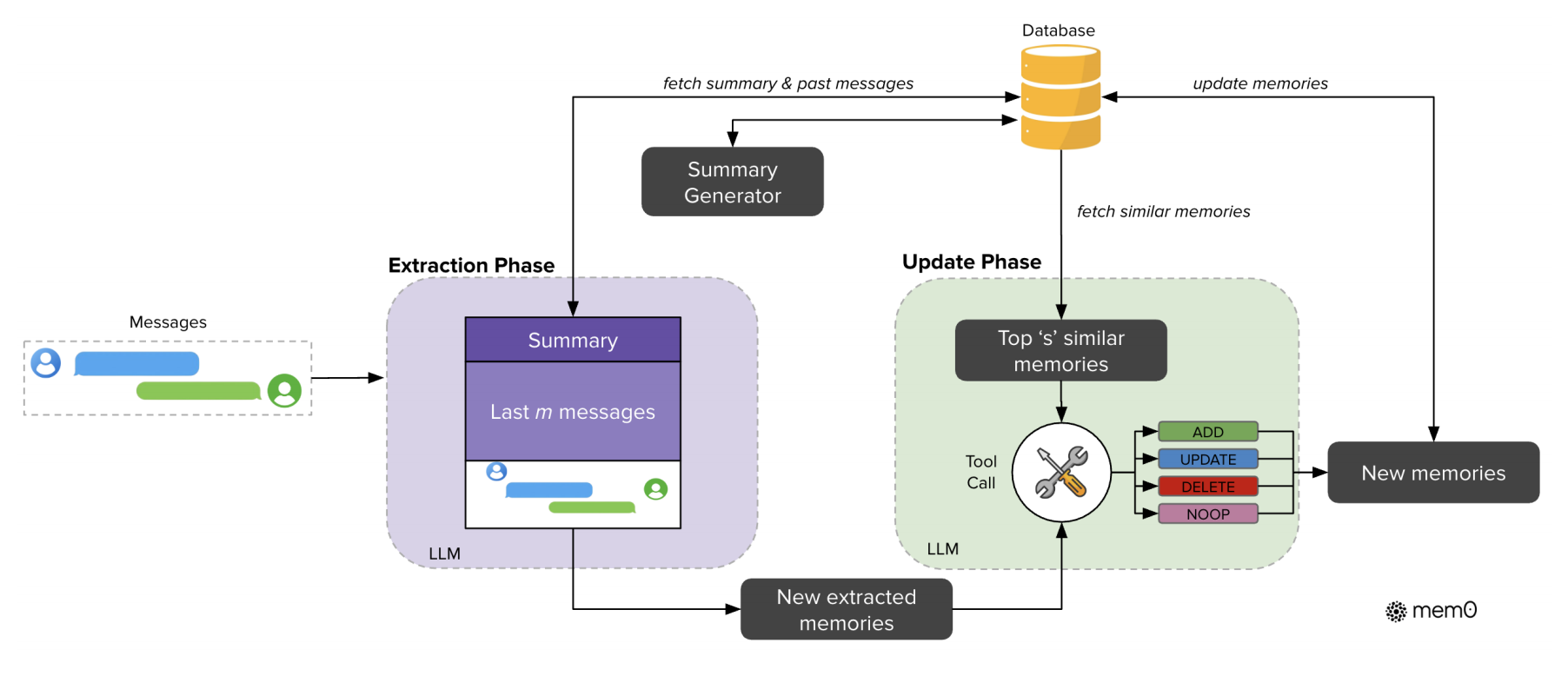
Native RAG
传统 RAG 以填充 prompt 的形式进行,从数据库中检索相关知识来填充。原始文档的内容通过切片,经过 Embedding Model 向量化,并存储到数据库中以备检索使用。
整个过程较为线性,检索方式也比较简单,不能保证最终的检索精度,其效果有一定局限性。
简单的 Native RAG 构建需要两个部分:offline(离线存储)和 online(在线检索)。这里使用 langchain 构建:
离线部分
首先准备好文档文本,导入相关库并加载文档内容到内存中:
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
# load document
loader = TextLoader("./knowledge.txt")
documents = loader.load()
接下来将文档拆分成段,进行 embedding 并将其持久化存储:
# split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap = 20,
)
splits = text_splitter.split_documents(documents)
# embed chunks
embeddings = OpenAIEmbeddings(
base_url="https://api.siliconflow.cn/v1",
model="Qwen/Qwen3-Embedding-0.6B",
)
# store chunks
vector_store = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory="./vector_store",
)
print("successfully stored chunks")
在线部分
online 环节更加简单,仅需将 query embed,然后进行向量检索,从离线环节构建得到的数据库中检索到相关文档内容,最后将文档内容作为上下文信息,填入到已有的 prompt template 中,调用模型进行内容生成。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.schema import HumanMessage
embeddings = OpenAIEmbeddings(
base_url="https://api.siliconflow.cn/v1",
model="Qwen/Qwen3-Embedding-0.6B",
)
vectorstore = Chroma(persist_directory="./vector_store", embedding_function=embeddings)
query = "什么是RAG?"
documents = vectorstore.similarity_search(query, k=3)
context = "\n".join([doc.page_content for doc in documents])
prompt = PromptTemplate(
template="""
你是一个专业的问答助手。请根据以下参考文档回答用户的问题。
如果参考文档中没有相关信息,请诚实地说不知道,不要编造答案。
参考文档:{context}
用户问题:{query}
回答:
""",
input_variables=["context", "query"]
)
chain = prompt | ChatOpenAI(
model="THUDM/glm-4-9b-chat",
temperature=0,
max_retries=3,
base_url="https://api.siliconflow.cn/v1",
api_key=API_KEY,
)
result = chain.invoke({"context": context, "query": query})
print(result.content)
Agentic RAG
Native RAG 的不足之处:
- 一次性检索:一般一下子检索
Top-K文档 chunks,无法按需求递进检索; - 查询力度差:只会根据相似度检索,不会进一步查看文件元数据;
- 缺乏任务拆解:问题可能需要先定位文件、再选片段、再比对与总结,Native RAG 往往缺少这样的多步拆解能力,也不会回溯重试,按语义改写原始查询等。
Agentic RAG 的思路是将 RAG 的过程“工具化”:提供 search tools,模型的检索利用这些 tools 进行,LLM 使用一个 tool use 的循环,获取到足够合适的信息后再生成。
Agentic 需要的能力:
- Planning / Reflection(一般可以体现在 Long COT thinking 过程中)
- tool use / Multi-Agent Collaboration(一般体现在 tools 的调用中)
- Multi-Step inference
(1).png)
- 让 LLM 作为“智能体(Agent)”充当控制器,结合一组工具(检索、查看元数据、读取片段等)执行“思考→行动→观察”的循环(Reason–Act–Observe)。
- 在回答之前,按需多轮调用工具,逐步从“找到相关文件”走到“读取关键片段”,最后基于被读取的证据组织答案,并给出引用。
主要有两种实现方式,一种是基于 tools & prompts 的 RAG,另一种是基于 RL 的 RAG。
基于 tools & prompts 的 RAG
ReAct 是一个常见的 Agent 实现方式,因此只要给 LLM 配备合适的 Tool以及适当的引导 Prompt,就可以将一个 Native RAG 转换成 Agentic RAG。
在 Agentic RAG 经典项目 chatbox 里,主要定义了四种关键的 tools:
query_knowledge_base
在知识库中进行语义检索,快速找到候选文件或chunks。通常作为最基础的检索工具get_files_meta
查看候选文件的元信息(如文件名、大小、chunk 数量),帮助模型决定“读哪几个文件的哪部分”。read_file_chunks
按文件ID + chunkIndex精读具体片段,用于“取证”。建议一次只读少量最相关的chunk,以降低噪声。list_files
列出知识库中的文件清单,作为兜底浏览或当搜索线索不充分时的探索手段。
这些 tools 具体在 Agentic RAG 里是怎么应用的呢?举个例子来说,query_knowledge_base 就是根据 query 最基础的查找,根据语义检索定位 chunks;紧接着,如果模型决策当前获取的信息不充足,需要补充上下 chunks 里的信息,那么可以通过调用 read_file_chunks 函数来补充。
同时,由于整个过程被拆解为多个 LLM 的调用决策,模型还可以根据当前判断,主动修改要检索的原始 query 信息,从而实现更好的检索。
Agentic RAG 的简单实现如下,大致分为三个环节:
- offline:构建文档数据库,定义文件数据类、文件元数据、文件
chunks分块方式、检索方法; - offline:定义知识库管理的调用函数,也就是几种模型要用到的工具
tools; - online:初始化模型,传入定义好的
tools,定义提示词模版,引导模型多步决策进行检索;
源代码如下:
from typing import List, Dict
import json
from dataclasses import dataclass
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
@dataclass
class FileChunk:
"""文件片段"""
file_id: int
chunk_index: int
content: str
@dataclass
class FileInfo:
"""文件信息"""
id: int
filename: str
chunk_count: int
status: str = "done"
class MockKnowledgeBaseController:
"""模拟知识库控制器 - 内存版本,用于演示"""
def __init__(self):
# 模拟一些文档数据
self.files = [
FileInfo(1, "rag_introduction.md", 5),
FileInfo(2, "llm_fundamentals.md", 4),
FileInfo(3, "vector_search.md", 3),
FileInfo(4, "prompt_engineering.md", 4),
]
# 模拟文档内容片段
self.chunks = {
(1, 0): FileChunk(
1,
0,
"RAG (Retrieval-Augmented Generation) 是一种结合检索和生成的技术,通过从外部知识源检索相关信息来增强大语言模型的生成能力。",
),
(1, 1): FileChunk(
1,
1,
"RAG 的优点包括:1) 能够访问最新信息,2) 减少模型幻觉,3) 提供可追溯的信息来源,4) 无需重新训练模型即可更新知识。",
),
(1, 2): FileChunk(
1,
2,
"RAG 的缺点包括:1) 检索质量直接影响生成效果,2) 增加了系统复杂度,3) 对向量数据库的依赖,4) 可能存在检索延迟。",
),
(1, 3): FileChunk(
1,
3,
"传统 RAG 系统通常采用固定的检索-生成流程,无法根据问题复杂度动态调整策略。",
),
(1, 4): FileChunk(
1,
4,
"Agentic RAG 通过引入智能体,使系统能够自主决策何时检索、如何检索以及检索多少内容,从而提升复杂问题的处理能力。",
),
(2, 0): FileChunk(
2,
0,
"大语言模型 (LLM) 是基于 Transformer 架构的深度学习模型,通过预训练学习语言的统计规律。",
),
(2, 1): FileChunk(
2, 1, "LLM 的核心能力包括自然语言理解、生成、推理和少样本学习等。"
),
(2, 2): FileChunk(
2, 2, "LLM 的局限性包括知识截止时间、可能产生幻觉、计算资源消耗大等。"
),
(2, 3): FileChunk(
2,
3,
"工具调用是 LLM 的重要扩展能力,使模型能够与外部系统交互,执行复杂任务。",
),
(3, 0): FileChunk(
3,
0,
"向量搜索是 RAG 系统的核心组件,通过将文本转换为向量表示来实现语义相似度匹配。",
),
(3, 1): FileChunk(
3,
1,
"常见的向量搜索算法包括 FAISS、Chroma、Pinecone 等,各有不同的性能特点。",
),
(3, 2): FileChunk(
3,
2,
"向量搜索的效果很大程度上依赖于embedding模型的质量和索引构建策略。",
),
(4, 0): FileChunk(
4,
0,
"提示工程是优化大模型表现的重要技术,包括设计有效的提示模板、上下文管理等。",
),
(4, 1): FileChunk(
4, 1, "良好的提示设计原则包括:清晰明确、提供示例、结构化输出格式等。"
),
(4, 2): FileChunk(
4, 2, "Agent 系统的提示设计需要考虑工具调用的策略指导和错误处理机制。"
),
(4, 3): FileChunk(
4, 3, "系统提示词应该明确定义 Agent 的角色、能力边界和行为规范。"
),
}
def search(self, kb_id: int, query: str) -> List[Dict]:
"""模拟语义搜索 - 基于关键词匹配"""
query_lower = query.lower()
results = []
for (file_id, chunk_idx), chunk in self.chunks.items():
content_lower = chunk.content.lower()
# 简单的关键词匹配评分
score = 0
keywords = [
"rag",
"agentic",
"优缺点",
"优点",
"缺点",
"llm",
"检索",
"生成",
"向量",
"搜索",
]
for keyword in keywords:
if keyword in query_lower and keyword in content_lower:
score += 1
if score > 0 or any(word in content_lower for word in query_lower.split()):
file_info = next(f for f in self.files if f.id == file_id)
results.append(
{
"file_id": file_id,
"chunk_index": chunk_idx,
"filename": file_info.filename,
"score": score + 0.5, # 基础分
"preview": chunk.content[:100] + "..."
if len(chunk.content) > 100
else chunk.content,
}
)
# 按分数排序并返回前5个
results.sort(key=lambda x: x["score"], reverse=True)
return results[:5]
def getFilesMeta(self, kb_id: int, file_ids: List[int]) -> List[Dict]:
"""获取文件元信息"""
result = []
for file_id in file_ids:
file_info = next((f for f in self.files if f.id == file_id), None)
if file_info:
result.append(
{
"id": file_info.id,
"filename": file_info.filename,
"chunk_count": file_info.chunk_count,
"status": file_info.status,
}
)
return result
def readFileChunks(self, kb_id: int, chunks: List[Dict[str, int]]) -> List[Dict]:
"""读取具体的文件片段"""
result = []
for chunk_spec in chunks:
file_id = chunk_spec.get("fileId")
chunk_index = chunk_spec.get("chunkIndex")
chunk = self.chunks.get((file_id, chunk_index))
if chunk:
result.append(
{
"file_id": file_id,
"chunk_index": chunk_index,
"content": chunk.content,
"filename": next(
f.filename for f in self.files if f.id == file_id
),
}
)
return result
def listFilesPaginated(self, kb_id: int, page: int, page_size: int) -> List[Dict]:
"""分页列出文件"""
start = page * page_size
end = start + page_size
files_slice = self.files[start:end]
return [
{
"id": f.id,
"filename": f.filename,
"chunk_count": f.chunk_count,
"status": f.status,
}
for f in files_slice
]
# 初始化模拟的知识库控制器
kb_controller = MockKnowledgeBaseController()
knowledge_base_id = 1 # 模拟的知识库ID
# 定义四个核心工具
@tool("query_knowledge_base")
def query_knowledge_base(query: str) -> str:
"""Query a knowledge base with semantic search"""
results = kb_controller.search(knowledge_base_id, query)
return json.dumps(results, ensure_ascii=False, indent=2)
@tool("get_files_meta")
def get_files_meta(fileIds: List[int]) -> str:
"""Get metadata for files in the current knowledge base."""
if not fileIds:
return "请提供文件ID数组"
results = kb_controller.getFilesMeta(knowledge_base_id, fileIds)
return json.dumps(results, ensure_ascii=False, indent=2)
@tool("read_file_chunks")
def read_file_chunks(chunks: List[Dict[str, int]]) -> str:
"""Read content chunks from specified files in the current knowledge base."""
if not chunks:
return "请提供要读取的chunk信息数组"
results = kb_controller.readFileChunks(knowledge_base_id, chunks)
return json.dumps(results, ensure_ascii=False, indent=2)
@tool("list_files")
def list_files(page: int = 0, pageSize: int = 10) -> str:
"""List all files in the current knowledge base. Returns file ID, filename, and chunk count."""
results = kb_controller.listFilesPaginated(knowledge_base_id, page, pageSize)
return json.dumps(results, ensure_ascii=False, indent=2)
def create_agentic_rag_system():
"""创建 Agentic RAG 系统"""
# 工具清单
tools = [query_knowledge_base, get_files_meta, read_file_chunks, list_files]
# 行为策略(系统提示)
SYSTEM_PROMPT = """你是一个 Agentic RAG 助手。请遵循以下策略逐步收集证据后回答:
1. 先用 query_knowledge_base 搜索相关内容,获得候选文件和片段线索
2. 根据搜索结果,选择最相关的文件,可选择性使用 get_files_meta 查看详细文件信息
3. 使用 read_file_chunks 精读最相关的2-3个片段内容作为证据
4. 基于读取的具体片段内容组织答案
5. 回答末尾用"引用:"格式列出实际读取的fileId和chunkIndex
重要原则:
- 不要编造信息,只基于实际读取的片段内容回答
- 若证据不足,请说明并建议进一步搜索的方向
- 优先选择评分高的搜索结果进行深入阅读
"""
# 模型与 Agent
llm = ChatOpenAI(
# model="gpt-3.5-turbo", # 使用 OpenAI 默认模型便于测试
temperature=0,
max_retries=3,
# 如需使用其他API,可配置 base_url
base_url="https://api.siliconflow.cn/v1",
model="THUDM/glm-4-9b-chat",
)
agent = create_react_agent(llm, tools, prompt=SYSTEM_PROMPT)
return agent
def main():
"""主函数 - 演示 Agentic RAG 的工作流程"""
print("🚀 初始化 Agentic RAG 系统...")
agent = create_agentic_rag_system()
print("\n📚 模拟知识库包含以下文件:")
for file in kb_controller.files:
print(f" - {file.filename} ({file.chunk_count} chunks)")
print("\n" + "=" * 80)
print("💬 开始问答演示")
print("=" * 80)
# 测试问题
question = "请基于知识库,概述 RAG 的优缺点,并给出引用。"
print(f"\n❓ 问题: {question}")
print("\n🤔 Agent 思考与行动过程:")
print("-" * 50)
# 调用 Agent
result = agent.invoke({"messages": [("user", question)]})
print("======")
final_answer = result["messages"][-1].content
print(result)
if __name__ == "__main__":
main()