原文链接:https://arxiv.org/abs/2504.19413
Background & Motivation
论文针对现有 Agent 系统记忆能力有限,从而导致长时间对话时,容易忘记过去的信息或是给出错误解答的问题,尝试设计一种记忆架构来维护一个“记忆库”,从而帮助 Agent 在每次解决问题时,能够调用已有记忆解决问题,并能不断更新记忆。

为了弥补这一缺陷,本文提出了 Mem0,一种记忆架构,它能够动态地提取和整合对话中的关键信息,让 AI 系统能记住重要内容并跨会话持续对话。进一步,论文还提出了 Mem0g,在 Mem0 的基础上加入了知识图谱,构建图结构记忆。
Method
Mem0
Mem0 的架构核心在于记忆提取与记忆更新机制,旨在确保 AI 系统能够动态地提取对话中的关键信息,并有效地更新其记忆库。这个过程分为两个主要阶段:记忆提取(Extraction) 和 记忆更新(Update)。
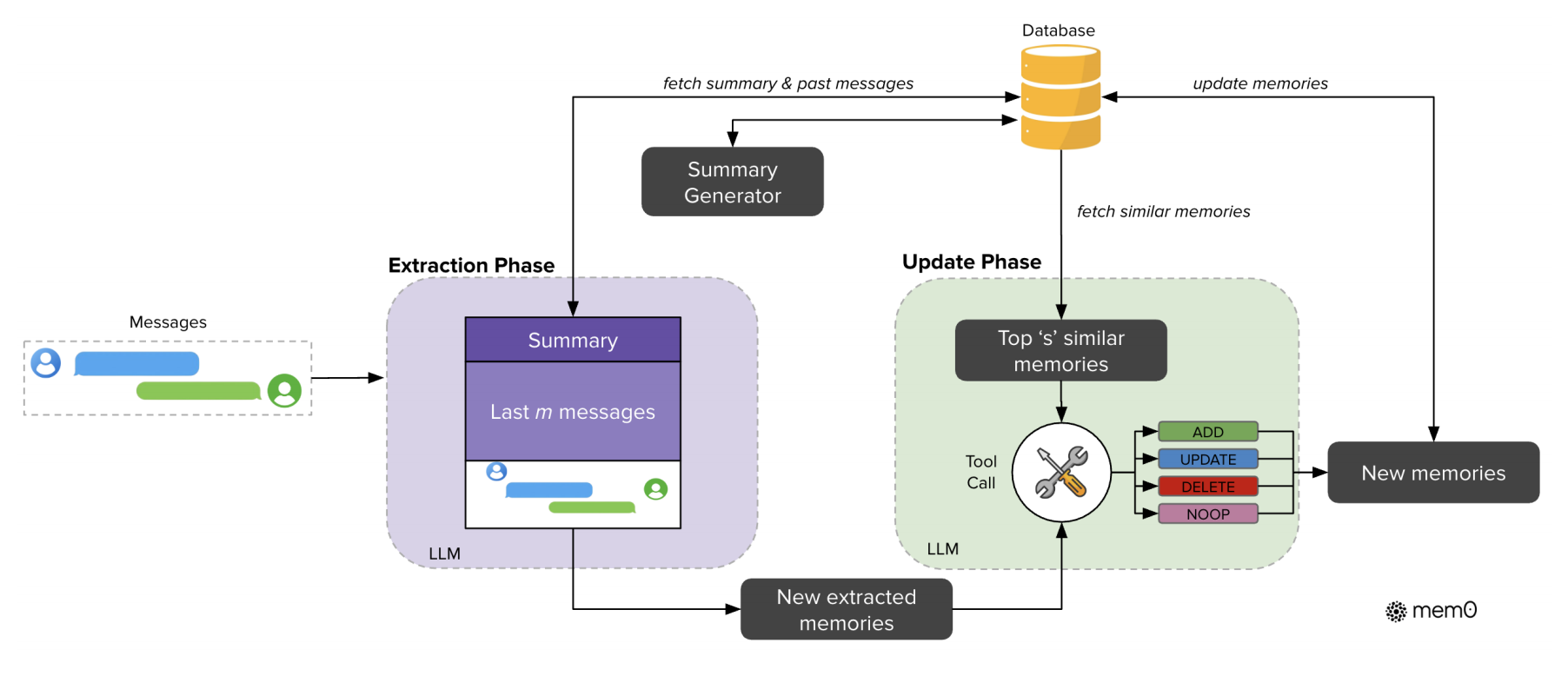
提取阶段
当系统接收到一个新的消息对(如用户提问和AI回答)时,提取阶段便会启动。为了准确理解当前对话的上下文,系统会结合两种信息源:
- 全局上下文:从数据库中检索的整个对话的摘要 $S$,提供对话的宏观主题。
- 局部上下文:最近消息序列 ${m_{t-m},…,m_{t-2}}$。
组合成一个完整的提示(prompt)P,输入给LLM实现的抽取函数 ϕ。LLM会基于这些信息,抽取出本轮对话中值得记忆的关键信息(如“用户是素食主义者”),形成一组候选记忆。
在摘要生成阶段,会采用一个异步生成模块。当新的对话消息进入系统后,指导大模型根据对话信息生成摘要:
def _create_procedural_memory(self, messages, metadata=None, prompt=None):
"""
# 异步摘要生成模块:创建程序化记忆(会话摘要)
# 该函数接收对话消息,使用LLM生成一个摘要,并将其存储为特殊类型的记忆
Args:
messages (list): 待处理的对话消息列表
metadata (dict): 存储元数据信息
prompt (str, optional): 自定义提示词,默认使用系统提示
"""
logger.info("Creating procedural memory")
# 1. 构建系统提示和用户消息,用于指导LLM生成摘要
parsed_messages = [
{"role": "system", "content": prompt or PROCEDURAL_MEMORY_SYSTEM_PROMPT},
*messages,
{
"role": "user",
"content": "Create procedural memory of the above conversation.",
},
]
try:
# 2. 使用LLM生成对话的摘要记忆
procedural_memory = self.llm.generate_response(messages=parsed_messages)
except Exception as e:
logger.error(f"Error generating procedural memory summary: {e}")
raise
if metadata is None:
raise ValueError("Metadata cannot be done for procedural memory.")
# 3. 标记这是一个程序化记忆(会话摘要)
metadata["memory_type"] = MemoryType.PROCEDURAL.value
# 4. 为摘要生成向量嵌入
embeddings = self.embedding_model.embed(procedural_memory, memory_action="add")
# 5. 创建记忆并存储在向量数据库中
memory_id = self._create_memory(procedural_memory, {procedural_memory: embeddings}, metadata=metadata)
capture_event("mem0._create_procedural_memory", self, {"memory_id": memory_id, "sync_type": "sync"})
# 6. 返回创建的记忆结果
result = {"results": [{"id": memory_id, "memory": procedural_memory, "event": "ADD"}]}
return result
Mem0 会将 会话摘要 和 最近消息 结合起来(很常见的全局和局部信息结合的思想),与当前的新消息(用户和助手的最新一轮对话)一起,生成一个 综合提示(P)。这个提示会被送入一个提取函数,通过大语言模型(LLM)来处理和提取出一组 候选记忆(Ω)。这些候选记忆是与当前对话相关的关键信息,用于后续更新知识库中的记忆。
def _add_to_vector_store(self, messages, metadata, filters, infer):
"""
提取记忆功能:处理消息并提取记忆事实
该函数实现了记忆的提取和存储过程
"""
# 如果不需要生成记忆片段,则直接存储原始消息(按原样存储)
if not infer:
returned_memories = []
for message in messages:
if message["role"] != "system":
message_embeddings = self.embedding_model.embed(message["content"], "add")
memory_id = self._create_memory(message["content"], message_embeddings, metadata)
returned_memories.append({"id": memory_id, "memory": message["content"], "event": "ADD"})
return returned_memories
# 1. 解析对话消息,形成上下文
parsed_messages = parse_messages(messages)
# 2. 构建提示,使用最近消息窗口作为上下文
if self.config.custom_fact_extraction_prompt:
system_prompt = self.config.custom_fact_extraction_prompt
user_prompt = f"Input:\n{parsed_messages}"
else:
system_prompt, user_prompt = get_fact_retrieval_messages(parsed_messages) # 提取记忆的system prompt自己看源码吧,比较长这里就不贴了
# 3. 使用LLM提取事实(候选记忆)
response = self.llm.generate_response(
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
response_format={"type": "json_object"},
)
# 4. 解析LLM输出,获取候选记忆
try:
response = remove_code_blocks(response)
new_retrieved_facts = json.loads(response)["facts"] # 候选记忆列表
except Exception as e:
logging.error(f"Error in new_retrieved_facts: {e}")
new_retrieved_facts = []
# 5. 准备从向量数据库检索相似记忆,以便后续进行更新决策
retrieved_old_memory = []
new_message_embeddings = {}
for new_mem in new_retrieved_facts:
# 为每个候选记忆生成向量嵌入
messages_embeddings = self.embedding_model.embed(new_mem, "add")
new_message_embeddings[new_mem] = messages_embeddings
# 检索向量数据库中与候选记忆语义相似的现有记忆
existing_memories = self.vector_store.search(
query=new_mem,
vectors=messages_embeddings,
limit=5,
filters=filters,
)
# 收集相似的现有记忆
for mem in existing_memories:
retrieved_old_memory.append({"id": mem.id, "text": mem.payload["data"]})
提取出的候选记忆并不会被直接存入数据库,而是会进入更新阶段,以确保记忆库的一致性和无冗余。该过程通过一个智能的“工具调用(Tool Call)”机制实现,具体流程如下:
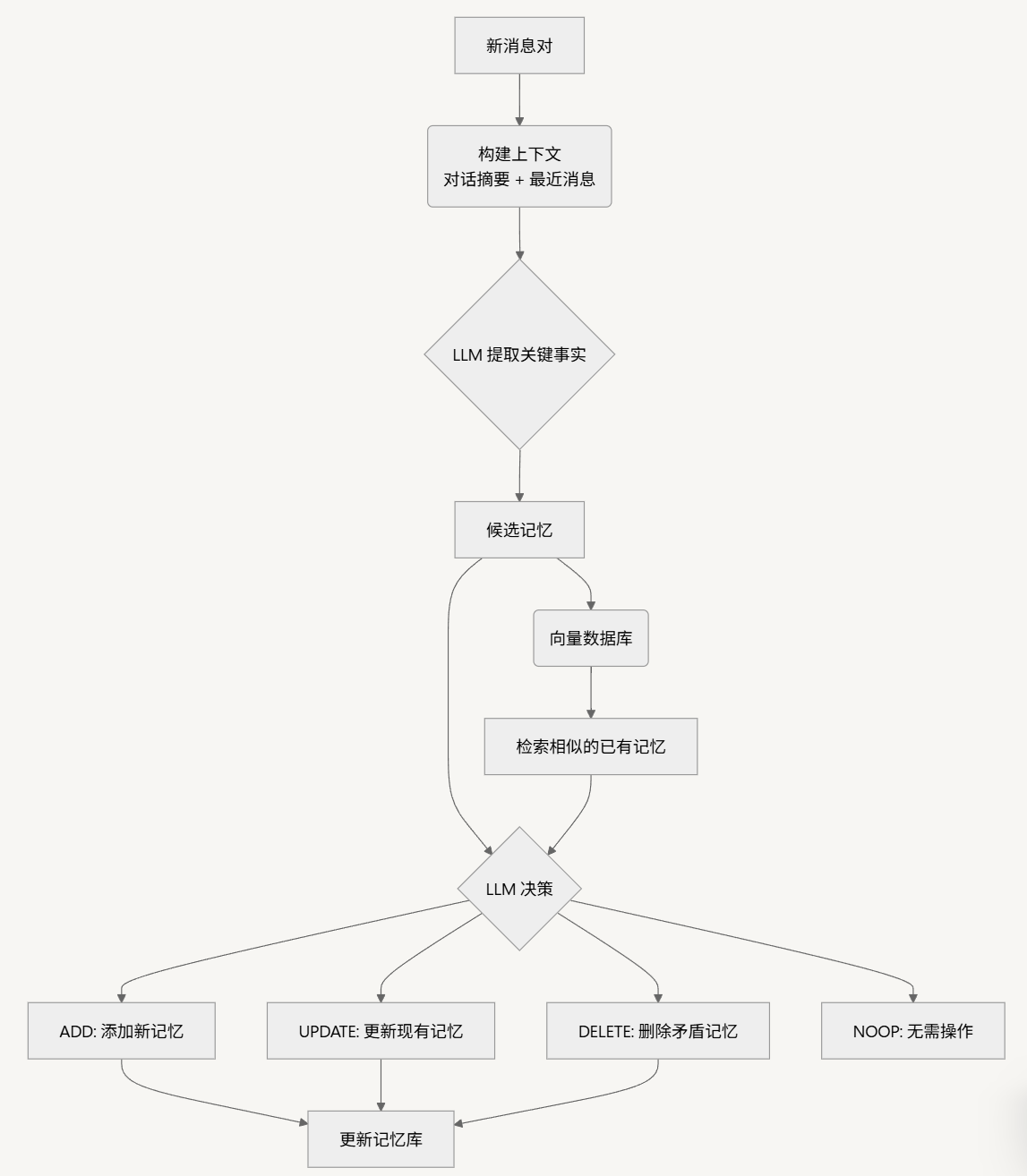
Mem0 首先会检索出与候选记忆语义最相似的若干个现有记忆(向量数据库向量检索)。然后通过function call的形式调用记忆更新工具来更新记忆。工具有4个:
- ADD:如果候选记忆是全新的信息,则添加。
- UPDATE:如果候选记忆是对现有信息的补充或更新,则进行修改。
- DELETE:如果候选记忆与现有信息相矛盾,则删除旧信息。
- NOOP:如果候选记忆是重复或无关的,则不执行任何操作。
当现有记忆与新提取的候选记忆存在冲突时,Mem0 会决定是否删除、更新或添加新记忆。
Mem0g
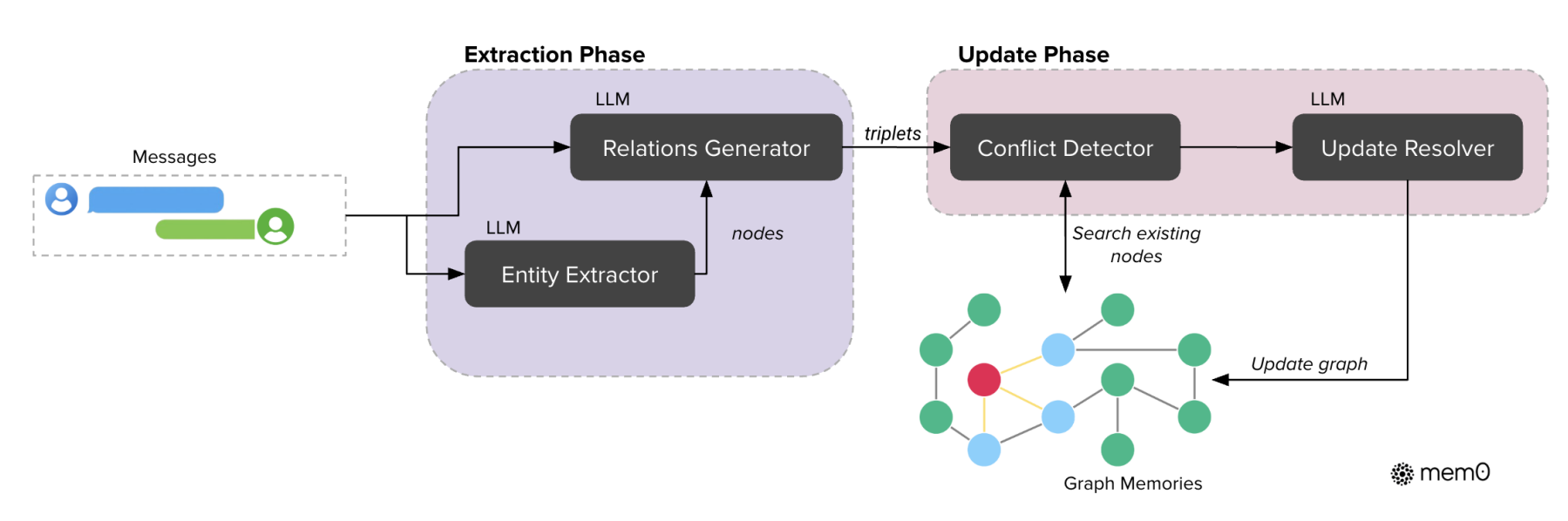
Mem0g 引入了传统知识图谱的思想来增强其对复杂关系的处理能力。与 Mem0 主要通过文本和摘要来管理记忆不同,Mem0g 通过三元组方式将记忆存储为头节点、尾节点和关系边的图,这种结构能更好地捕捉了不同实体之间的关系。同样是两个阶段(提取和更新)。
以图 $G=(V,E,L)$ 建模记忆(实体、关系、Label)
首先通过一个实体提取模块从对话中识别出所有相关的实体(例如人物、地点、事件等)及实体类别。随后,系统会通过关系生成模块根据对话上下文建立实体之间的关系,形成一组三元组(如实体 A 、实体 B及关系 R)。这些三元组也就组成了一个记忆知识图谱。
Mem0g在抽取实体和关系的时候就是用大模型+prompt完成,没有用传统nlp中实体识别或者关系抽取的方法。并且,它是采用两阶段完成,即先实体抽取,再关系生成。
每个entity(node)包含三部分信息:
- entity type classification:用于标记这个实体属于哪一类
- embedding vector:实体语义含义的向量表示,便于后续做语义相似度检索和推理
- metadata: 主要包括创建时间戳(creation timestamp),用于记录这个实体被加入知识图谱的时间,有助于时序推理
class MemoryGraph:
def __init__(self, config: MemoryConfig = MemoryConfig()):
"""
知识图谱记忆模块初始化
负责实体提取、关系生成和图谱维护
"""
self.config = config
# 初始化图数据库存储
self.graph_store = GraphStoreFactory.create(
self.config.graph_store.provider, self.config.graph_store.config
)
# 初始化LLM用于实体和关系提取
self.llm = LlmFactory.create(self.config.llm.provider, self.config.llm.config)
# 初始化嵌入模型用于语义相似度计算
self.embedding_model = EmbedderFactory.create(
self.config.embedder.provider,
self.config.embedder.config,
self.config.vector_store.config,
)
def add(self, message, filters=None):
"""
向知识图谱添加新信息
实现从文本中提取实体和关系并构建知识图谱
"""
filters = filters or {}
# 1. 使用LLM提取实体
# 实体提取模块:从文本中识别相关实体及其类别
entity_prompt = self._get_entity_extraction_prompt(message)
entity_response = self.llm.generate_response(
messages=[{"role": "user", "content": entity_prompt}],
response_format={"type": "json_object"},
)
try:
# 解析LLM返回的实体列表
entity_response = remove_code_blocks(entity_response)
entity_data = json.loads(entity_response)
entities = entity_data.get("entities", [])
# 如果没有提取到实体,直接返回
if not entities:
return []
# 2. 使用LLM生成实体间关系
# 关系生成模块:根据上下文建立实体之间的语义关系
relation_prompt = self._get_relation_extraction_prompt(message, entities)
relation_response = self.llm.generate_response( # 核心还是构建prompt+调用大模型的方式
messages=[{"role": "user", "content": relation_prompt}],
response_format={"type": "json_object"},
)
# 解析LLM返回的关系列表
relation_response = remove_code_blocks(relation_response)
relation_data = json.loads(relation_response)
relations = relation_data.get("relations", [])
# 3. 将实体和关系添加到图数据库中
added_entities = []
for relation in relations:
# 处理头实体
source_entity = relation.get("source")
source_entity_type = relation.get("source_type")
# 处理尾实体
target_entity = relation.get("target")
target_entity_type = relation.get("target_type")
# 处理关系
relationship = relation.get("relationship")
# 将实体和关系信息添加到图数据库
if source_entity and target_entity and relationship:
# 为实体和关系生成向量嵌入,用于后续相似性检索
source_entity_embeddings = self.embedding_model.embed(source_entity, "add")
target_entity_embeddings = self.embedding_model.embed(target_entity, "add")
# 添加到图数据库并记录结果
result = self.graph_store.add_triple(
source=source_entity,
source_type=source_entity_type,
relationship=relationship,
target=target_entity,
target_type=target_entity_type,
source_embedding=source_entity_embeddings,
target_embedding=target_entity_embeddings,
metadata=filters
)
added_entities.append({
"source": source_entity,
"source_type": source_entity_type,
"relationship": relationship,
"destination": target_entity,
"destination_type": target_entity_type
})
return added_entities
except Exception as e:
logger.error(f"Error in entity/relation extraction: {e}")
return []
def _get_entity_extraction_prompt(self, message):
"""
生成实体提取的提示词
指导LLM识别文本中的各类实体
"""
return """You are an entity extraction system. Your task is to identify the most important entities in the given text.
An entity can be a person, place, organization, product, or concept. For each entity, provide its type.
Format your response as a JSON object with a single key "entities", containing a list of entity objects.
Each entity object should have "name" (the entity) and "type" fields.
Here is the text to analyze:
/```
{message}
/```
JSON Response:
""".format(message=message)
def _get_relation_extraction_prompt(self, message, entities):
"""
生成关系提取的提示词
指导LLM识别已提取实体之间的关系
"""
entity_names = [e.get("name") for e in entities]
entity_str = ", ".join(entity_names)
return """You are a relationship extraction system. Your task is to identify meaningful relationships between the entities in the given text.
Text:
/```
{message}
/```
Entities: {entities}
For each relationship you identify, specify:
1. The source entity
2. The type of the source entity
3. The relationship (a verb or phrase describing how entities are connected)
4. The target entity
5. The type of the target entity
Only create relationships that are explicitly or strongly implied in the text.
Format your response as a JSON object with a single key "relations", containing a list of relationship objects.
JSON Response:
""".format(message=message, entities=entity_str)
Mem0g 通过 图数据库 Neo4j进行节点和边的检索。具体来说,Mem0g 会计算新提取的实体与现有节点之间的语义相似度,并根据阈值决定是否更新或添加新的节点和关系。这种操作也是通过 FC 来完成的。
记忆检索功能 则是其与 Mem0 另一个显著的区别点。Mem0g 在处理查询时,采用了 双重检索策略,一方面是基于 实体 的检索,首先通过识别查询中的关键实体并在图中找到相应节点,之后探索这些节点的关联关系及对应的尾实体。另一方面,Mem0g 采用 语义三元组检索,即通过将整个查询转换为一个 向量表示,与图中的三元组进行匹配。(就是两种检索策略叠加使用,以期获得更全面的信息)
Experiments
在长对话记忆评测基准 LOCOMO 上,将 Mem0 和 Mem0-g 与六大类基线方法进行了全面对比,包括已有的记忆增强系统、多种配置的RAG、全上下文方法、开源记忆方案以及商业平台。
LOCOMO 包含 10 个长对话,每个对话约 600 轮、26000 tokens,跨多次会话。每个对话后有约 200 个问题及标准答案,问题类型包括 single-hop、multi-hop、temporal、open-domain
Evaluation Metrics:
Performance Metrics:
- **F1 Score (F1)**,传统的词级重叠指标;
- **BLEU-1 (B1)**,单词级 BLEU 分数;
- **LLM-as-a-Judge (J)**,综合评估回答的事实准确性、相关性、完整性和上下文适应性;
Deployment Metrics:
- Token Consumption(检索到的 context token 数量,反映系统的计算和成本效率);Latency,测量Search Latency和Total Latency。
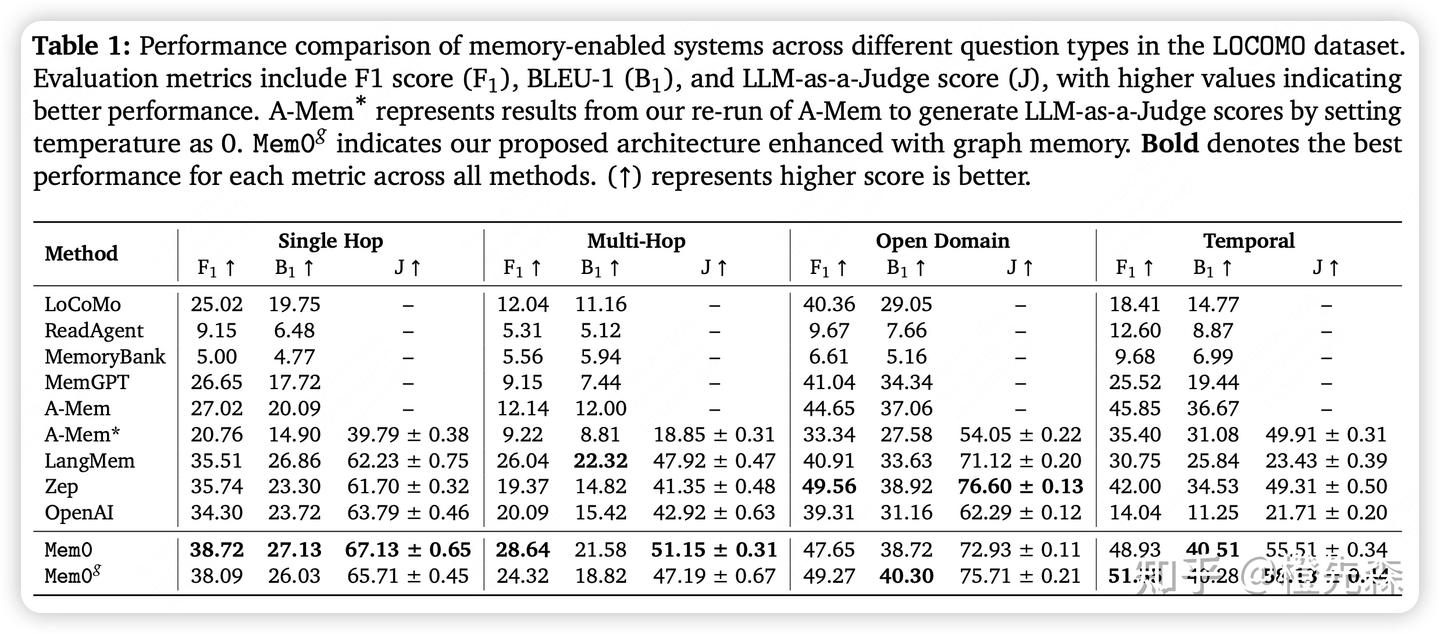
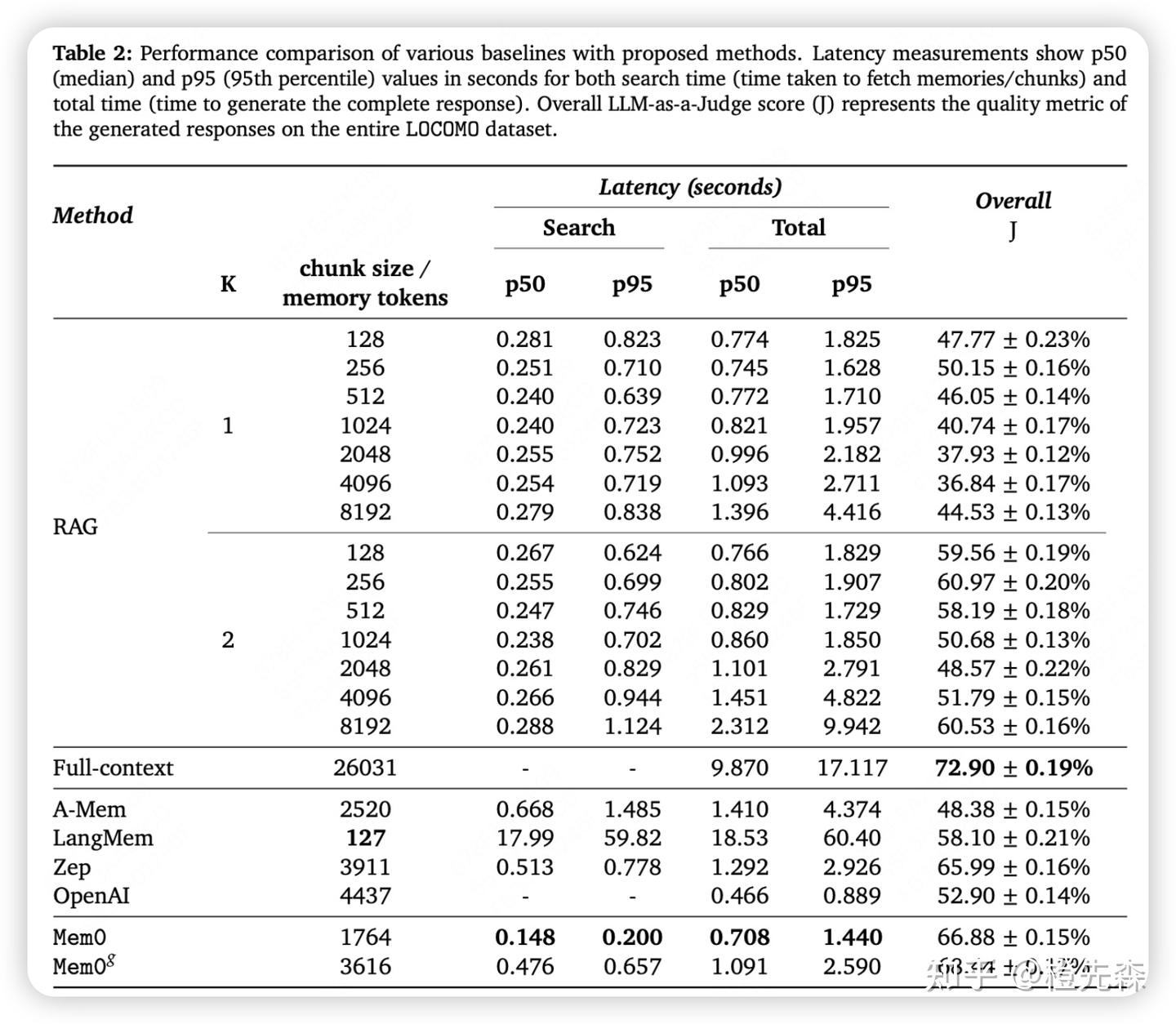
在计算效率方面,Mem0 和 Mem0g 都显著优于全上下文处理方法,尤其是在响应时间和 p95 上,二者分别减少了 91% 和 85% 的延迟。此外,Mem0g 在存储效率上略有增加,因为其图结构需要更多的内存空间。
My Thoughts
Mem0 是 Agent Memory 领域的经典作,理解起来并不困难。
和 A-Mem 相比较,其实主要也就是两点不同,仍然是 Agent Memory 里最关键的两点:
- 记忆存储:Mem0 是摘要+最近消息引导大模型生成记忆,Mem0g 是图节点实体关系三元组形式,A-Mem 是笔记与链接形式;
- 记忆更新:A-Mem 和 Mem0 基本都是通过 Agent 自主决策判断,通过与以往记忆比对,判定当前记忆如何操作。


(1).png)