原文链接:https://arxiv.org/abs/2510.17281
Background
随着高质量数据枯竭,大模型 scaling law 已触及瓶颈,单纯靠增加参数的收益变得微乎其微。因而,近期的研究聚焦于如何从大模型系统优化方向,持续提升大模型的能力,并实现更高层次的智能。
持续学习的必要性:人脑通过与环境的持续交互,智力能够不断进化;现代信息检索系统通过服务用户并从交互中不断学习,能够持续提升性能。通过对比 LLM 与这两者,实现大模型长期持续地从交互中进一步提升能力,是达到更高层次智能的关键。其核心要素有两者:
- 成熟稳定的记忆结构。人类的海马体能够存储短期、长期记忆;搜索引擎则具备数据模块、算法模块来存储和处理查询请求。
- 高效的反馈分析 & 利用机制。人脑通过试错学习知识并积累经验;搜索引擎则通过用户反馈更新推荐算法。
目前尚缺乏完善的评估标准来衡量现有算法的进展并指导未来研究。现有针对LLM系统的记忆功能评估主要集中在检验其处理长上下文数据(如用户画像和对话历史)的能力。且忽视了持续学习的动态性,大多采用静态评估。
Benchmark
因此,本文提出名为MemoryBench的综合性基准测试框架,用于评估大型语言模型系统(LLMsys)的内存管理和持续学习能力。
Preliminary
对一个具备记忆和持续学习能力的LLM系统,从数学上可以对其做如下形式化定义:
LLMsys 的构成:
- 参数化记忆:$\theta$,指 LLM 本身的模型参数;
- 非参数化记忆: $M$,指外部存储的知识,如文档、数据库等。
系统运作流程:
- 系统接收用户的一系列任务查询 $Q$。
- 系统生成响应:$f(θ,M,Q)$。
- 在时间步 $t$,用户对系统针对查询 $q_t$ 产生的响应给出反馈:$s(q_t,f(θ_t,M_t,q_t))$。
- 到时间 $t$ 为止,所有的反馈构成了反馈日志: $S_t−1$。
系统需要根据积累的反馈日志 $S_t−1$ 来调整其参数化记忆 $θ_t$ 和非参数化记忆 $M_t$,调整的目的是为了最小化在下一个查询 $q_t$ 上的损失:$l(q_t,f(θ_t,M_t,q_t))$。
接着,受到神经科学和传统AI的启发,论文提出了一个针对 LLMsys 的记忆分类法,主要基于存储的知识类型进行划分:
记忆
│
├── 陈述性记忆:关于“是什么”的事实性知识。
│ │
│ ├── 语义记忆:与用户无关的通用知识。
│ │ └── 例子:教科书、维基百科、公共数据集。
│ │
│ └── 情景记忆:与特定用户相关的历史记录。
│ └── 例子:对话历史、用户个人资料、过往交互。
│
└── 程序性记忆:关于“如何做”的任务性知识。
└── 例子:任务的工作流程、解决方案的奖励信号、从成功/失败中总结的经验。
另外,LLM 领域的“反馈”一词常被泛化使用,因此论文借鉴信息检索的研究,提出了一个细致的反馈分类法:
用户反馈
│
├── 显式反馈:用户直接旨在评价系统输出质量的行为。
│ │
│ ├── 详细反馈:用户用自然语言明确指出错误并指导修正。
│ │ └── 例子:“你这里说错了,应该是...,请重写。”
│ │
│ └── 行动反馈:用户通过简单操作表达满意度。
│ └── 例子:点击“点赞”或“点踩”按钮。
│
└── 隐式反馈:用户在服务过程中产生的、非直接用于评价的间接行为信号。
└── 例子:点击“复制”按钮、在看到响应后关闭会话、用相似但更精确的提示开始新会话。
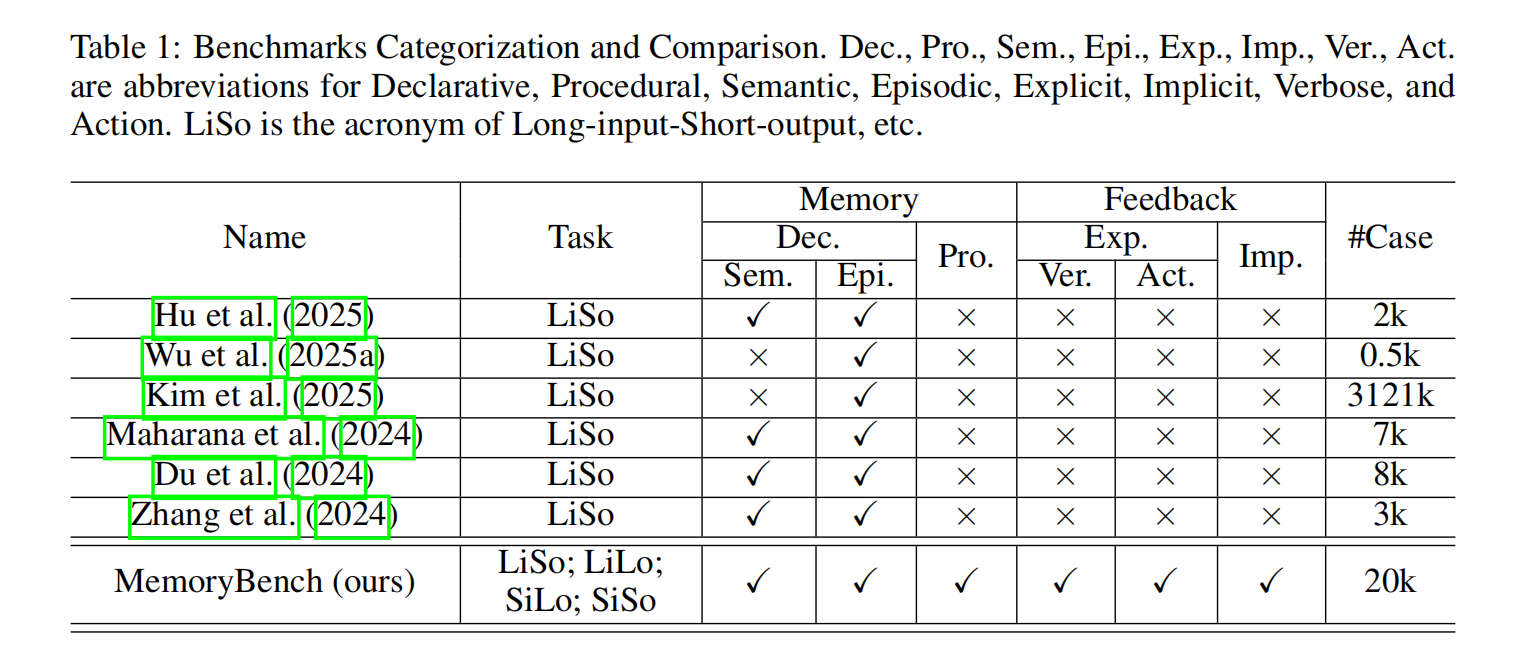
通过将 MemoryBench 与已有的6个 LLM 记忆基准进行全面对比,MemoryBench 具备如下优势:
MemoryBench是第一个同时提供所有类型记忆和反馈数据的基准。
现有基准大多只关注长输入-短输出的阅读理解任务,本质上是测试系统从给定上下文中提取答案的能力。
MemoryBench则包含了输入输出长度各异、领域多样的任务,使其成为评估LLMsys持续学习能力的独特资源。
Framework
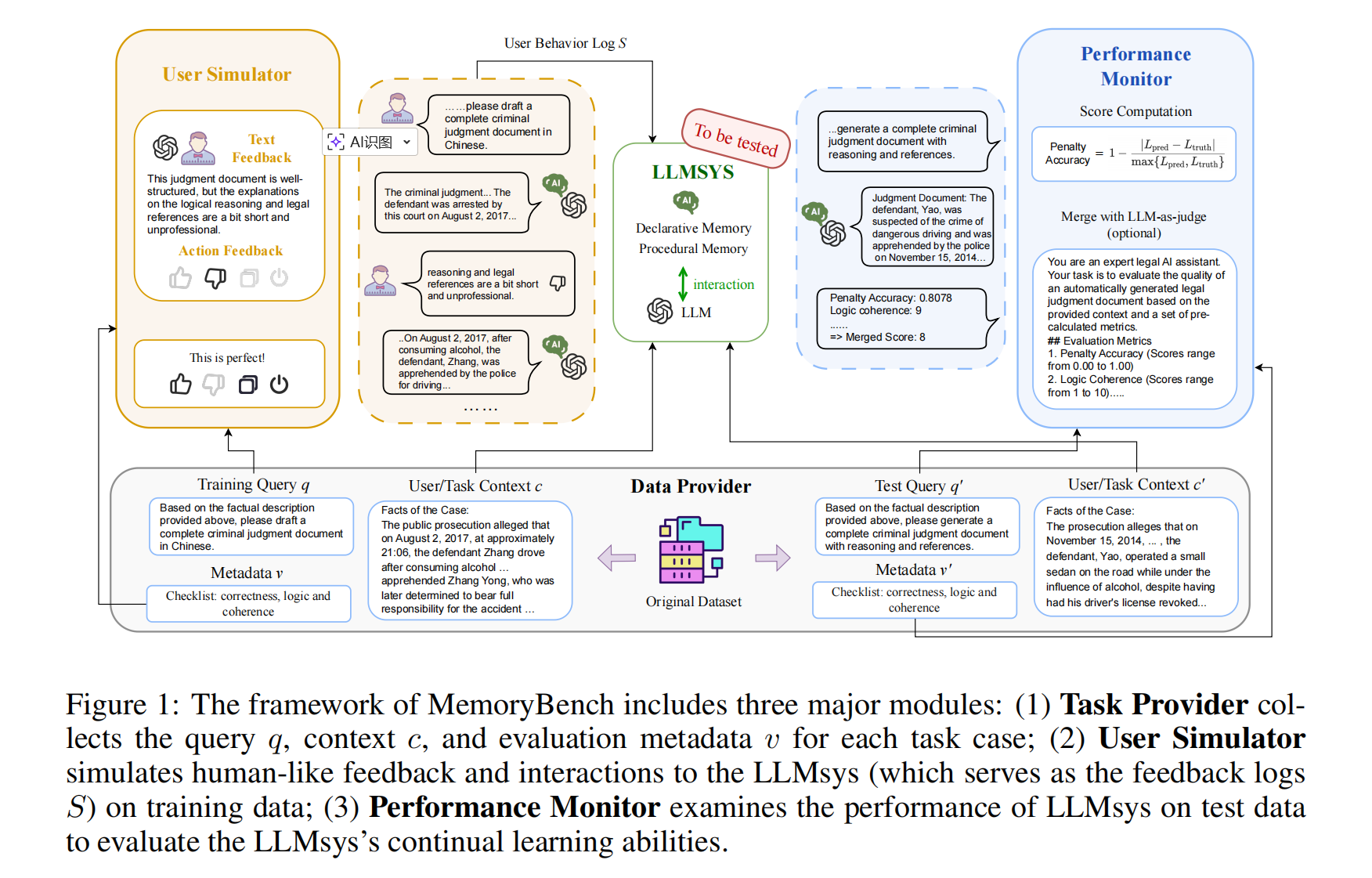
MemoryBench 框架主要包含三个核心模块:
- 任务提供模块:收集每个任务案例的查询 $q$、上下文 $c$ 及评估元数据 $v$;
- 用户模拟模块:通过训练数据向 LLMsys(即反馈日志 $S$)模拟类人交互反馈;
- 性能监控模块:通过测试数据评估 LLMsys 的持续学习能力。
整个流程如下:
首先,由任务提供模块产生训练和测试数据,训练数据用到用户模拟模块,结合反馈和标准答案,产出对话和反馈日志 $S$,这些日志会交给 LLMsys 训练记忆模块(让记忆模块工作起来,这里主要需要用到 $c$ 和 $S$)。
然后,LLMsys 再在测试数据上,回答测试数据的 queries,根据回答效果,对比答案或者用 LLM 评估,看看 LLMsys 的实际工作效果如何。
在大规模模拟真实用户反馈这一点上,MemoryBench 开发了一种混合反馈模拟机制。
- **对于具有可验证基准的
task**,直接使用客观指标比对。系统会把范数映射到一个预设的反馈模版,生成相应的显性和隐性反馈信号。 - **对于开放式、主观的
task**,采用 LLM 模拟用户的认知和行为反应。模拟器会根据特定用户画像模拟用户(包含用户背景、领域知识水平、评估标准等)。
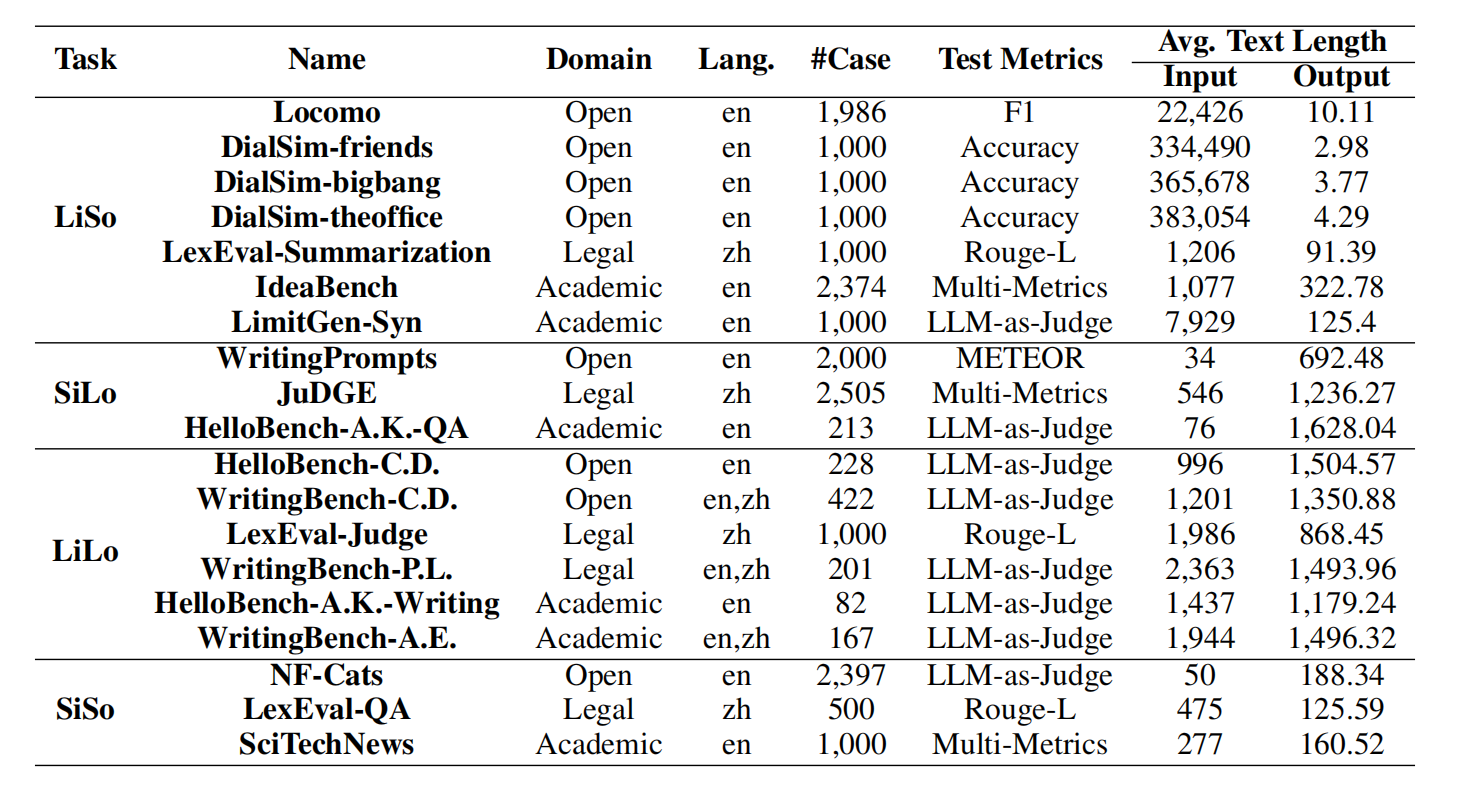
为了全面评估LLMsys的能力,论文从3个领域(开放域、法律、学术)、4种任务格式(LiSo, SiLo, LiLo, SiSo)和2种语言(中、英)中选取了11个公共数据集。
“A.K.”代表“学术与知识”,“A.E.”代表“学术与工程”,“C.D.”代表“创意与设计”,“P.L.”代表“政治与法律”。
无论原始数据集格式如何,论文都将其统一规范为 (q, v, c) 的三元组格式:
- **
q**:用户查询。 - **
v**:评估元数据(如标准答案、评分标准)。这是给“裁判”看的,用于最终打分。 c:任务上下文/语料(可选)。这是给LLMsys看的,作为其陈述性记忆的原材料。
具体在数据采样、划分中,论文的操作是:在每个分区内部,从包含的每一个数据集中,随机且均匀地抽取最多250个样本(如果数据集样本量小于250,则使用全部)。将这些抽取来的样本,按照 4:1 的比例 划分为训练集和测试集。
最后,将所有数据集的训练样本合并,形成该分区的最终训练集;所有测试样本合并,形成该分区的最终测试集。
Experiment
首先,为了全面评估,论文实现并测试了多种类型的基线方法,Base Model 均为 Qwen3-8B:
Vanilla(无记忆):直接使用 LLM 回答问题,没有任何记忆机制。这是最基础的对比基线。
朴素RAG方法:
- 检索器:分别使用稀疏检索(BM25)和密集检索(Qwen3-Embedding-0.6B)。
- 存储粒度:测试了两种方式:将整个对话会话存为一个文档(-S),或将每条消息存为独立文档(-M)。
- 这产生了 BM25-S, BM25-M, Embed-S, Embed-M 四个基线。
先进的基于记忆的 LLMsys:
- A-Mem:一种智能体记忆系统,能动态组织和演化记忆。
- Mem0:一种生产就绪的、可扩展的长时记忆架构。
- MemoryOS:一个受操作系统启发的分层记忆管理框架。
监督微调:针对“点赞”、“复制”这类动作反馈,额外实现了SFT基线,用于对比。
论文实验主要针对三个主要问题展开:
- 模拟的用户反馈是否有用?
- 不同的LLM系统在利用用户反馈进行持续学习方面表现如何?
- 现有基于记忆的LLM系统的主要局限和未来方向是什么?
Q1 Result
对于使用用户反馈的可靠性,通过以下实验验证,对比各任务场景下使用与未使用反馈的Vanilla方法(即骨干LLM)性能:
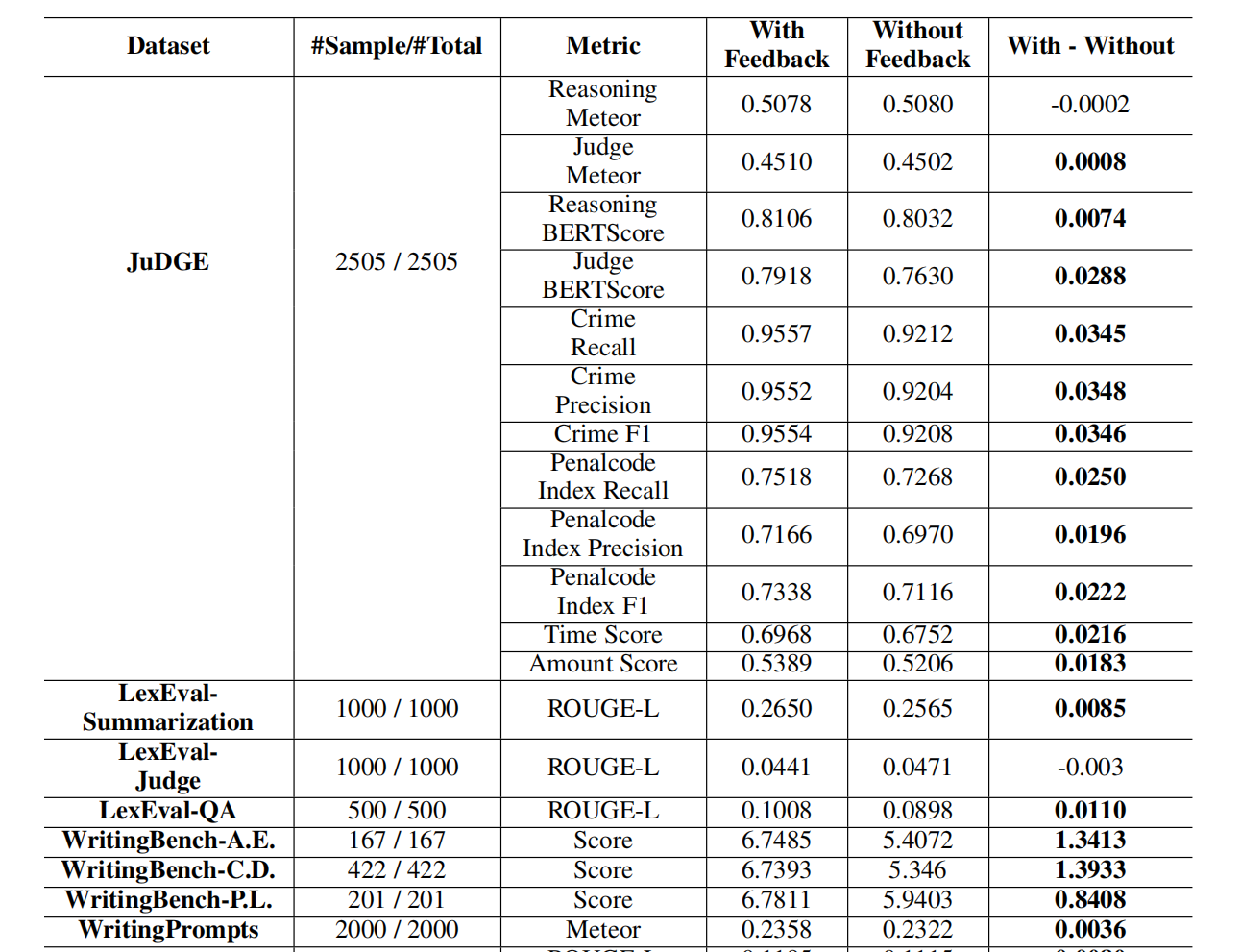
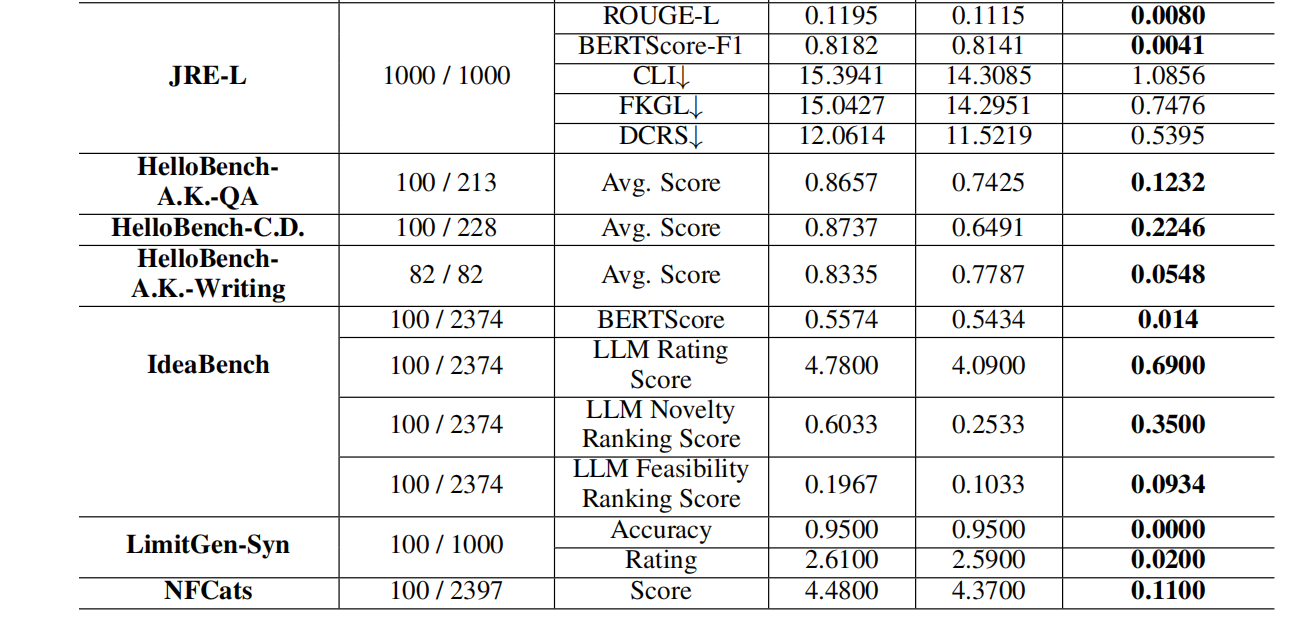
可以看到在大多数数据集上,使用反馈都带来了一定的性能提升。
Q2 & Q3 Result
论文使用不同的 baseline 实现框架中的 LLMsys,并对其进行了实验测试。具体的测试结果如下图所示(这个图看起来蛮抽象的,感觉不如直接拉个表直接一点):
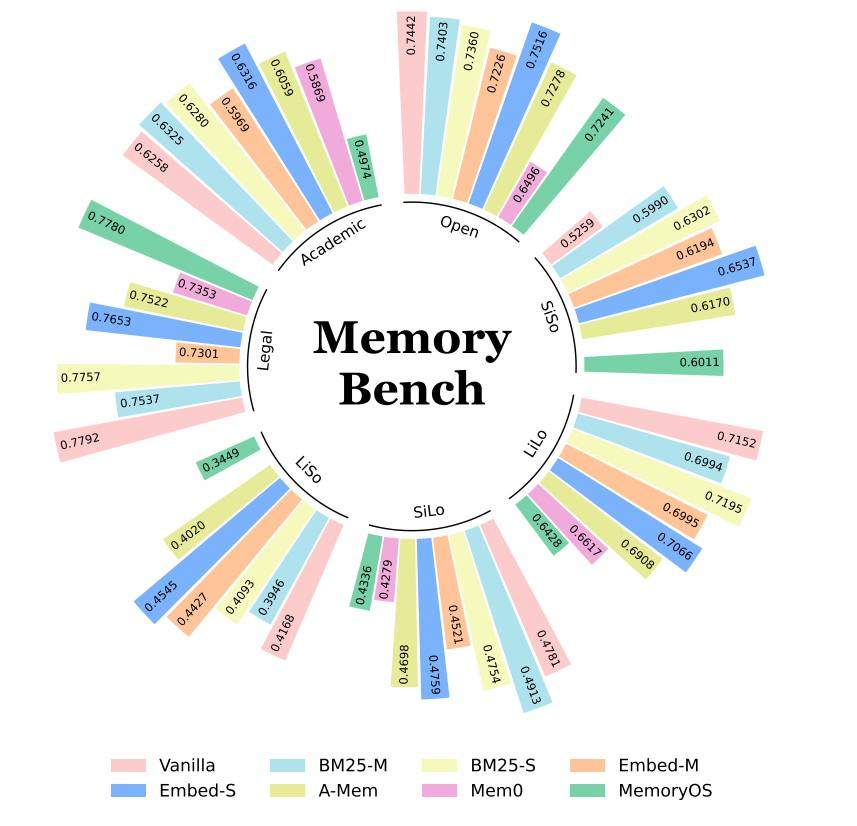
可以看到,所有基于先进记忆的LLM系统(即A-Mem、Mem0或MemoryOS)都无法持续超越仅使用任务上下文和反馈日志作为检索语料的RAG基准模型。
为探究该现象是否与我们采集的反馈信号类型相关,论文还使用“点赞”和“复制”等模拟操作反馈进行了实验,结果仍呈现相似趋势。
此外,这类系统在效果和效率上都存在明显不足,尤其在用户反馈量持续增加的持续学习场景中表现欠佳。基于记忆的方法在记忆输入上下文和进行在线推理时耗时极长,且任务间表现不一致。下图展示了不同格式任务中各类大模型系统(LLMsys)的内存处理时间(即处理单个测试用例的行为日志和任务上下文所需时间)与预测时间(即完成内存处理后生成测试用例响应所需时间):
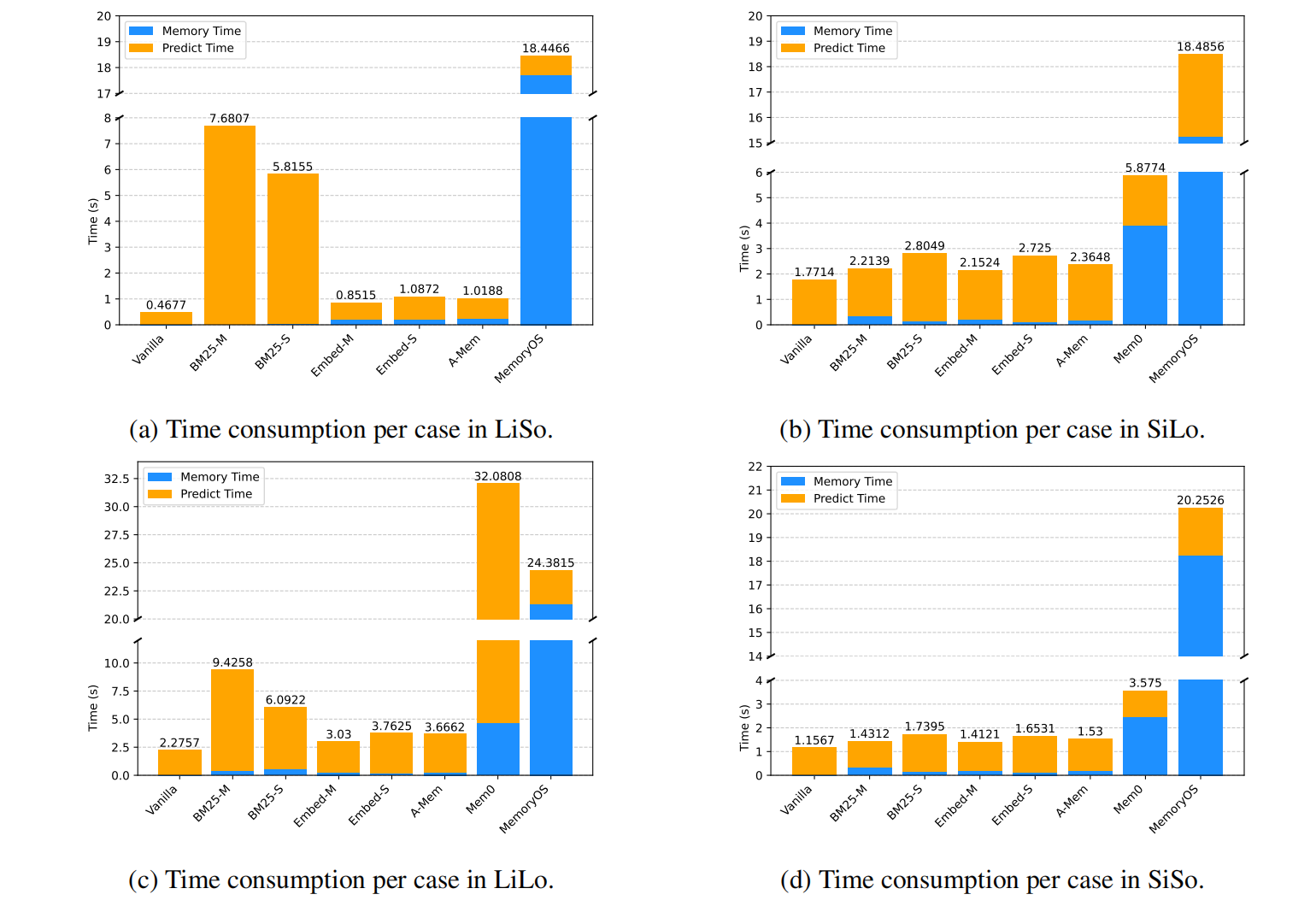
- Mem0 在处理长输入任务(如LiSo、LiLo)时内存处理时间较短,但在短输入任务(如SiLo、SiSo)时耗时较长。
- MemoryOS 在推理时间上表现出更好的一致性,但内存构建耗时较长(每个案例大多超过17秒)。
- A-MEM 在实验中是效率最高的基于记忆的 LLMsys,这可能得益于其简化的内存构建和检索流程。然而在多数情况下,其效果仍不及朴素的 RAG 基准模型。
实验中LLMsys的性能在训练过程中波动较大,尤其在学术和法律领域表现明显。这表明现有方法在持续学习中无法有效过滤和利用用户反馈。
Conclusion
论文的实验结果补充了 memory 方向考虑用户反馈的评测空白,感觉效果很值得参考。
可以看到现有的 Agent Mem 工作效果还非常有待继续优化和提升,并且大家很少关注效率成本的问题。不过 Mem 的工作本身就比 RAG 肯定要多出一部分成本和延迟,毕竟 RAG 只是单纯的检索工具,而 Mem 要涉及更新增删改等等操作。
后续可以参考这个 Bench 去测试 Mem 工作结合用户反馈的效果,而且结合反馈这一点感觉还是很值得去继续优化的。
(另外理论上来说我感觉离线评测 Mem 打不过 RAG 还在意料之中,但是在线一样也打不过就有点难绷了,,)