原文链接:https://arxiv.org/abs/2509.25911
Background & Motivation
现有记忆系统大多依赖预设指令和固定工具集,未经训练即可优化记忆构建,如 Mem0,MemGPT,MIRIX 等。然而,模型本身缺乏判断存储内容、结构设计及更新时机的内在能力,手动调整提示方案难以应对所有场景,模型泛化性较差——不知道该存储什么信息、如何组织、以及何时更新。
Mem-α 提供了一个全新的解决思路:通过强化学习让模型自己学会如何管理记忆,训练智能体掌握有效的内存管理策略。
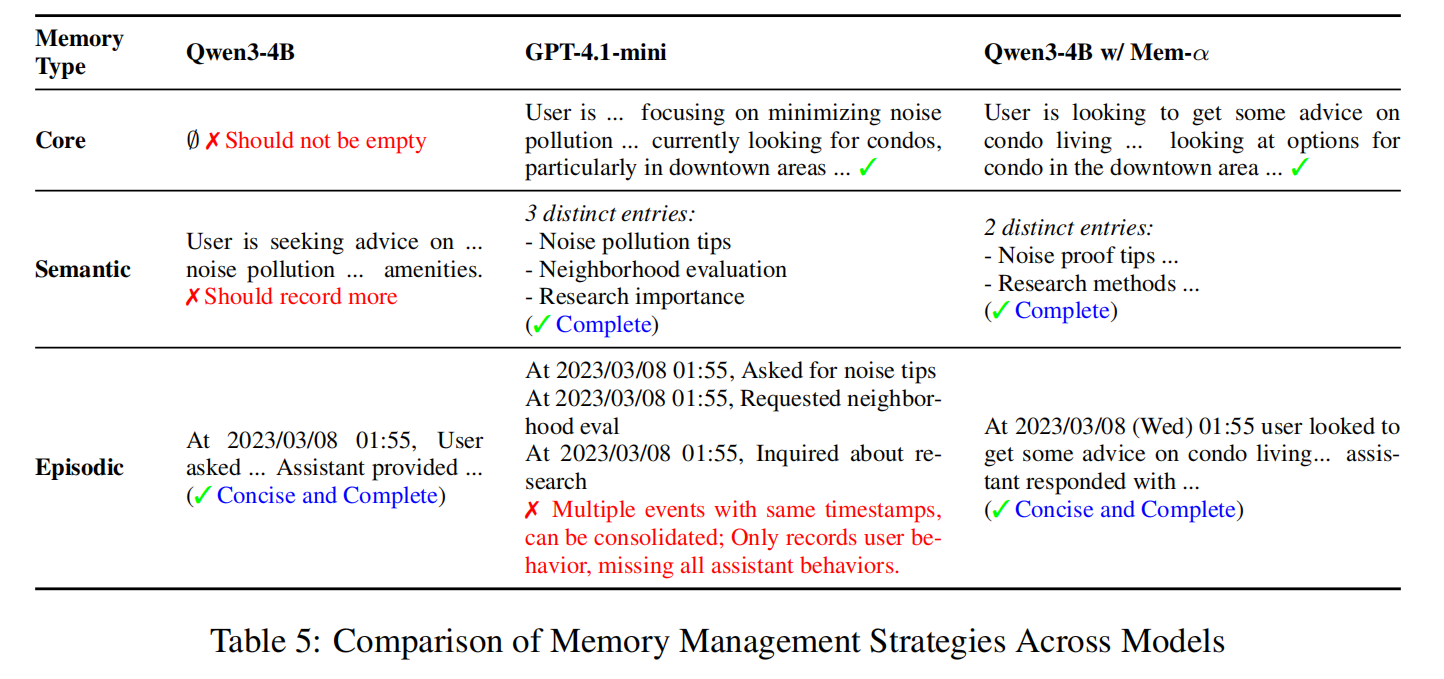
如上图所示,在管理三层记忆系统(核心记忆、情景记忆、语义记忆)时:
未训练的模型:尝试调用两个工具:
memory_update(更新核心记忆)和memory_insert(插入情景记忆),但在更新核心记忆时失败了,模型虽然试图使用工具,但选择能力和信息提炼能力很弱,导致记忆结构不完整、信息高度压缩和丢失——模型不知道应该把哪些核心信息提炼出来。Mem-α 训练后:能够正确地在各个记忆层级存储相应信息,模型学会了如何有效地使用工具,并能够构建一个结构清晰、信息丰富、分类明确的记忆系统。
Method
Mem-α 的核心洞察是:记忆管理是一个可以通过强化学习优化的序列决策问题。与传统方法的本质区别在于,利用 RL,模型不再依赖人工设计的规则,而是在实践中探索最优的记忆管理策略。
Memory Architecture
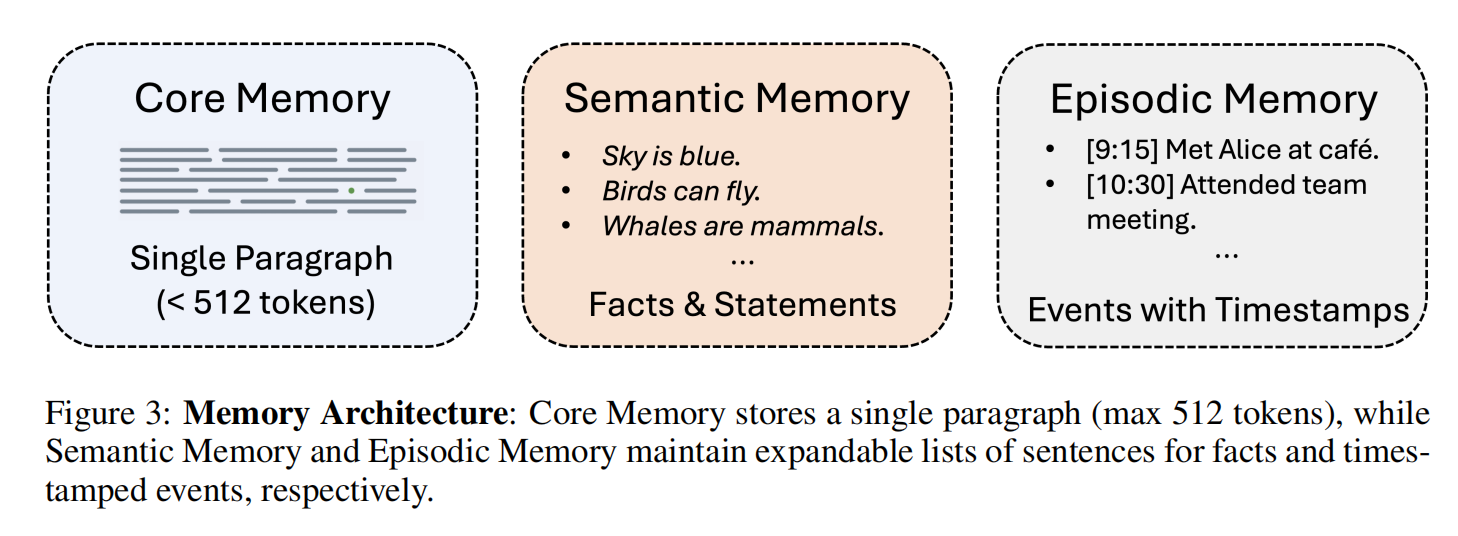
Mem-α 使用三层记忆系统架构:
- 核心记忆(Core Memory):存储用户的基本、持久信息,内容是角色、偏好、目标等长期稳定的特征。容量 512 tokens,精炼且关键。
- 情景记忆(Episodic Memory):记录具体事件和经历,内容是带时间戳的活动历史,以列表形式存储,如 “9:15 在咖啡馆遇见 Alice”,捕捉发生的事&何时发生。
- 语义记忆(Semantic Memory):存储结构化知识和事实,内容是概念、规则、专业知识、操作指南。是事实陈述,不依赖特定时间或情境,长期有用。
针对每种记忆类型,系统提供三类操作,插入(insert)、更新(update)、删除(delete),老三样。
Framework
Mem-α 将记忆构建建模为一个顺序决策过程,输入是信息块序列,以及评估问题集。
- 状态(State):在处理第
t个信息块时,状态是当前的信息块c_t和截至此时积累的记忆状态M_{t-1}。 - 动作(Action):智能体可以执行的动作
a_t是一个操作序列,例如a_t = (memory_insert(...), memory_update(...))。这意味着模型在看完一个信息块后,可以执行多个记忆操作来更新记忆。 - 策略(Policy):由语言模型参数化的策略
π(a_t | c_t, M_{t-1}),它根据当前状态决定要执行哪些记忆操作。 - 奖励(Reward):智能体在处理完整个对话序列后,才会根据其构建的最终记忆
M_n的质量获得奖励。这个奖励是延迟的,迫使智能体必须为长远目标(最终回答好问题)而规划记忆策略。
对于 Reward,Mem-α 设计了四个互补的奖励信号:
- 正确性奖励(r₁):这是最重要的奖励。在所有信息块处理完毕后,使用一个固定的 RAG 流程,基于最终记忆
M_n来回答一系列问题Q。答案的准确率(如 F1 分数)就是r₁。这直接优化了记忆的最终目标——支持准确的信息检索。 - 工具调用格式奖励(r₂):确保模型生成的工具调用格式正确、能成功执行。如果格式错误,操作就无法进行,这是学习的基础。
- 压缩奖励(r₃):鼓励模型用更精炼的语言存储信息,提高记忆效率。
r₃ = 1 - (记忆总长度 / 输入总长度)。 - 记忆内容奖励(r₄):确保每次记忆操作在语义上是合理的。例如,是否把事件正确地存入了情景记忆,把事实存入了语义记忆。这个奖励由一个“法官”模型(如 Qwen2.5-32B)根据预定义的规则来判断。
整个训练流程如下图所示,可以分为两个阶段:
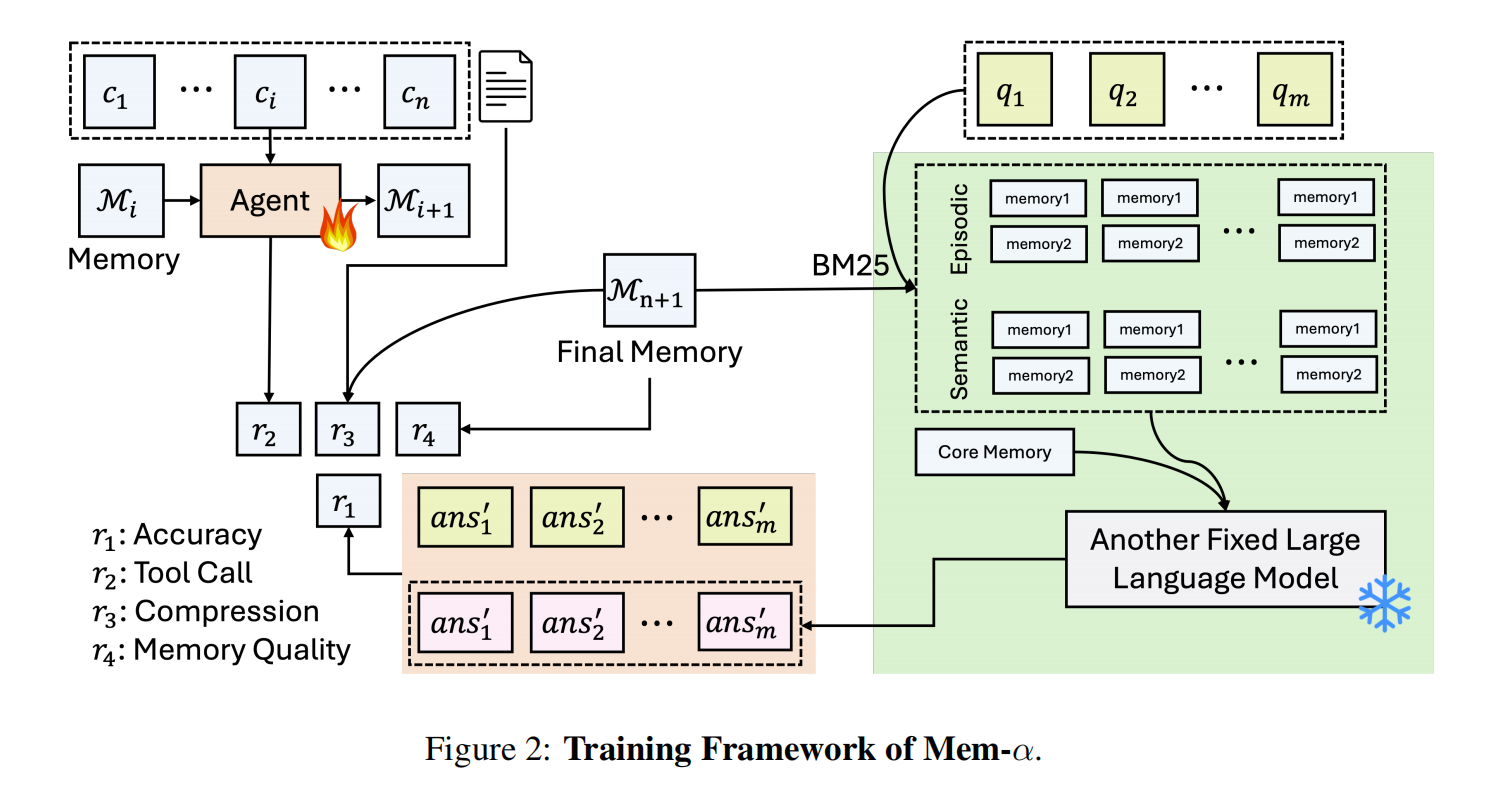
- 采样与交互:从数据集中采样一个完整的对话流(数据集的多个对话数据,一个batch批次的对话数据这样),然后 agent 逐步阅读对话块,根据当前状态(当前块+当前记忆)选择动作(记忆操作),并更新记忆状态。生成三种记忆;
- 评估与奖励:生成到最终记忆,使用 RAG 让一个冻结的 LLM 基于这个最终记忆(包含三部分),针对用户的 queries 做检索增强。根据这次回答的结果指标,计算出一个综合奖励
R; - 策略优化:通过 GRPO 算法,将总奖励
R回溯分配给整个动作序列中的每一步。通过梯度上升,更新 Agent 的策略模型参数,使其未来更倾向于做出能获得高奖励的决策。 - 重复这个操作,最终训练得到模型。
- 测试:部署训练好的Agent,它负责在真实对话中自主构建记忆,而后续的问答任务则由一个固定的RAG系统基于这些记忆来完成。
对于总奖励 R,定义为 $R=r1+r2,t+βr3+γr4,t$
累积多个对话序列(K条轨迹),然后使用 GRPO 算法计算群组相对优势,紧接着更新模型参数。
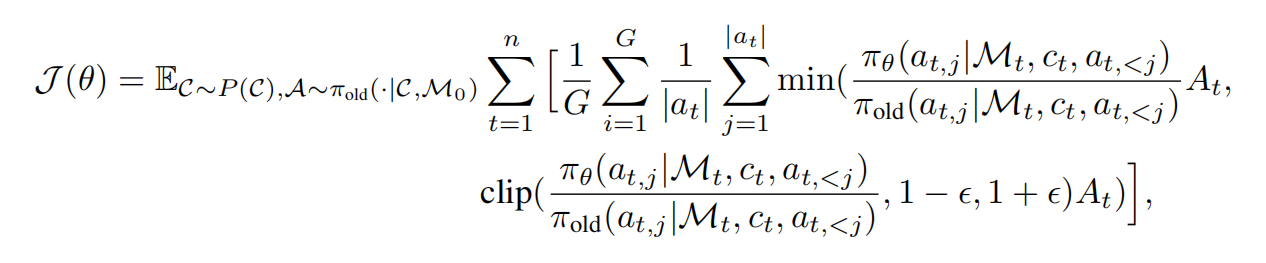
C ∼ P(C):从所有可能的对话流分布中采样一个具体的对话CA ∼ π_old(·|C, M₀):用旧的策略π_old根据对话C和初始空记忆M₀采样出一系列动作A对对话中的每一个时间步
t进行求和,在组内的多个轨迹上进行平均(G是组的大小),在单个时间步内的多个子动作上进行平均(|a_t|是第t步执行的子动作数量)。分子:新策略
π_θ在给定状态下选择动作a_{t,j}的概率分母:旧策略
π_old在相同状态下选择相同动作的概率
Experiment
Main Result
实验在 MemoryAgentBench 测试集上进行全面评估,对比了多个基线方法:长上下文模型(Long-Context)、检索增强生成(RAG)、记忆增强智能体(MemAgent、MEM1)。
关键发现:Mem-α 的训练完全基于最长 30k tokens 的样本,但在平均长度超过 300k tokens 的测试集上表现出色,展现了 10 倍以上的长度泛化能力。
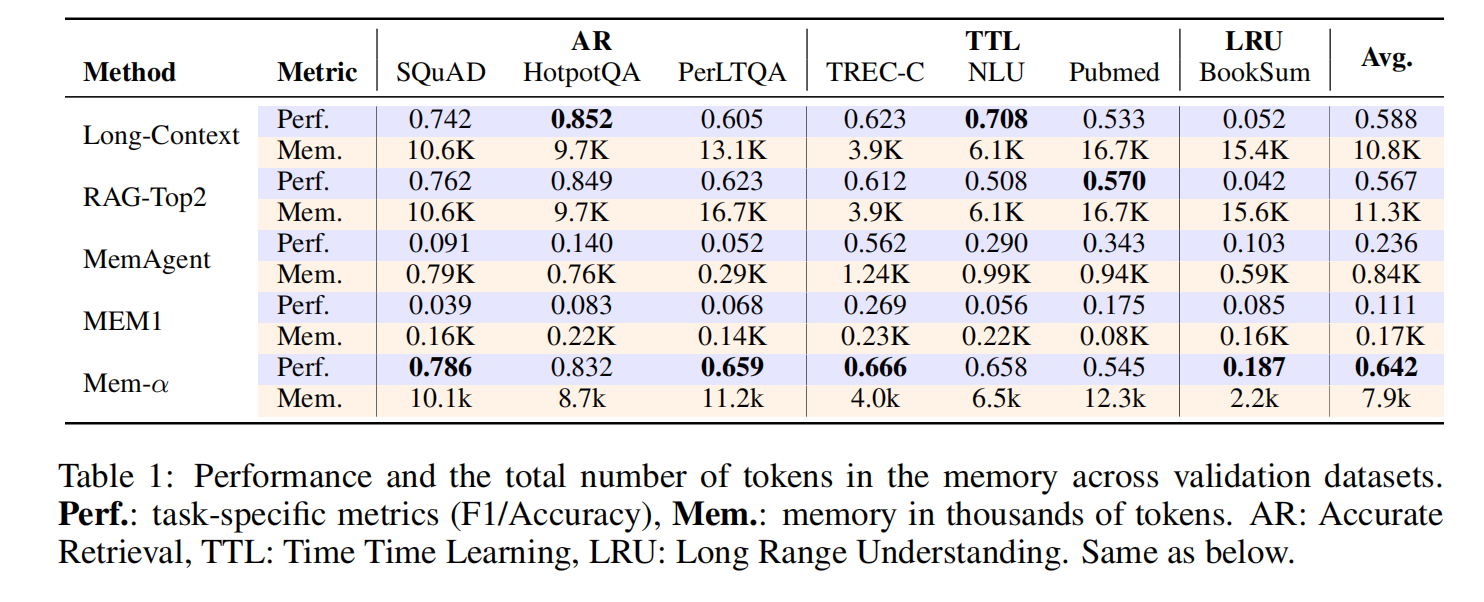

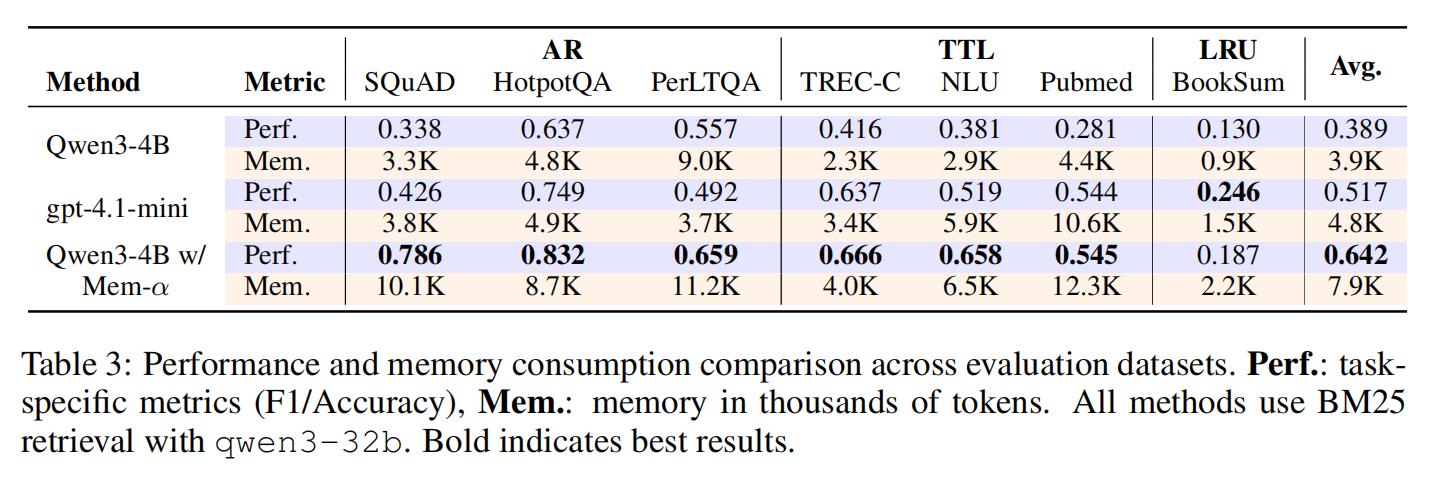
- 全任务优越性能:Mem-α 在所有指标上显著超越现有基线方法。在 MemoryAgentBench(表 2)上,我们观察到在精确检索(AR)和长期理解(LRU)任务上取得了特别显著的改进,展现出对未见分布的强大泛化能力。
- 高效的记忆压缩:与 Long-Context 和 RAG-Top2 相比,Mem-α 将记忆占用减少了约 50%,在保持高性能的同时显著降低了内存开销。
- 强大的长度泛化能力:尽管训练仅使用了平均长度小于 20K tokens 的文档,Mem-α 成功泛化到超过 400K tokens 的文档(在 MemoryAgentBench 的 Multi-Doc 数据集中最长达 474K),展现了训练框架在极端长度外推上的鲁棒性。
Ablation Result
- 消融强化学习(使用 RL 方法与否)
- 消融 RL 超参数
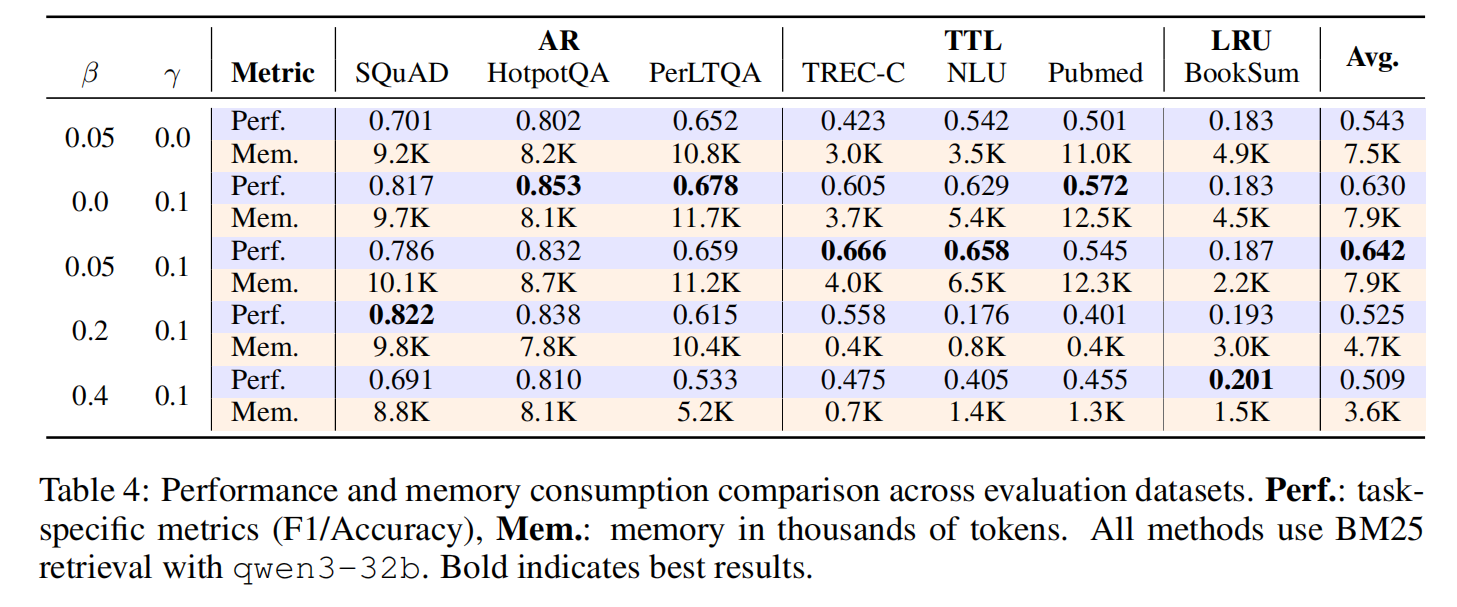
针对消融研究,可以得到如下结论:
- 记忆内容奖励(γ)对有效学习至关重要——将γ设为0会导致性能急剧下降,因为模型无法掌握有效的记忆构建策略,最终形成无法支持下游任务的无序记忆表征。
- 压缩率奖励(β)具有任务依赖性。在保持γ=0.1的情况下,增加β会导致记忆长度缩短,但性能会相应下降。
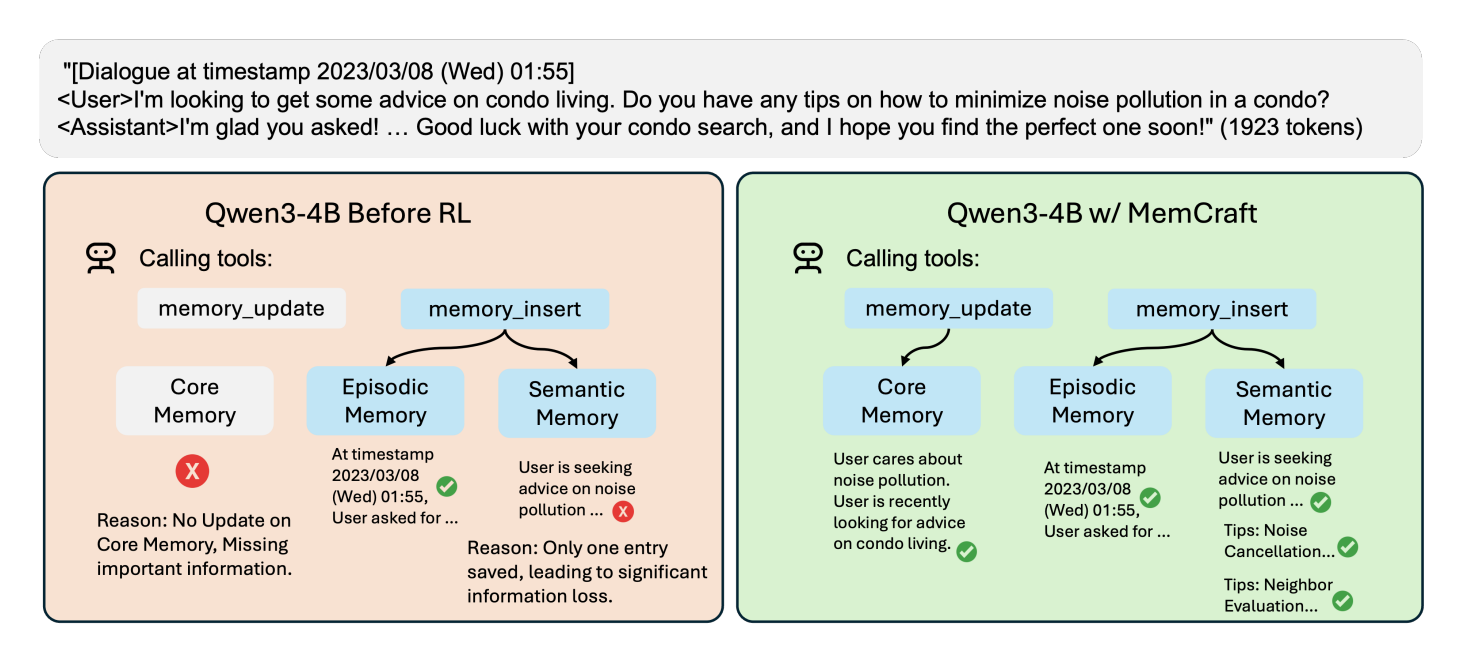
最后针对 RL 训练前后,论文还有一些实际案例对比: