原文链接:https://arxiv.org/abs/2510.04851
本文提出LEGOMem,一个面向多智能体系统的模块化过程记忆框架,旨在通过结构化的记忆构建、检索与分配机制,提升系统的规划、协调与执行能力。
Background & Motivation
现在基于 LLM 的智能体被广泛应用于自动化复杂多步骤工作流,如文档编辑、邮件处理和日程安排等。多智能体系统逐渐成为主流架构,一般由一个中心协调器负责任务规划与分发,多个任务智能体负责执行具体子任务。
论文指出,现有的大多数多智能体系统是无状态的:每次任务都从头开始执行,不利用历史执行经验。这限制了系统在复杂工作流中持续学习和提升的能力。而面向单智能体的记忆机制可能无法有效泛化到多智能体系统上。
多智能体系统相比单智能体,在记忆这一方面主要面临的问题有三点:
- 缺乏过程记忆:无法从成功的历史轨迹中提取可复用的任务分解与执行模式。
- 角色记忆不匹配:协调器需要高层次规划记忆,而任务智能体需要具体工具使用记忆。
- 记忆检索粒度不灵活:现有方法如 Synapse 和 AWM 主要面向单智能体,多智能体系统中不同角色的记忆需求不同,记忆粒度也不一致,适应性不足。
Method
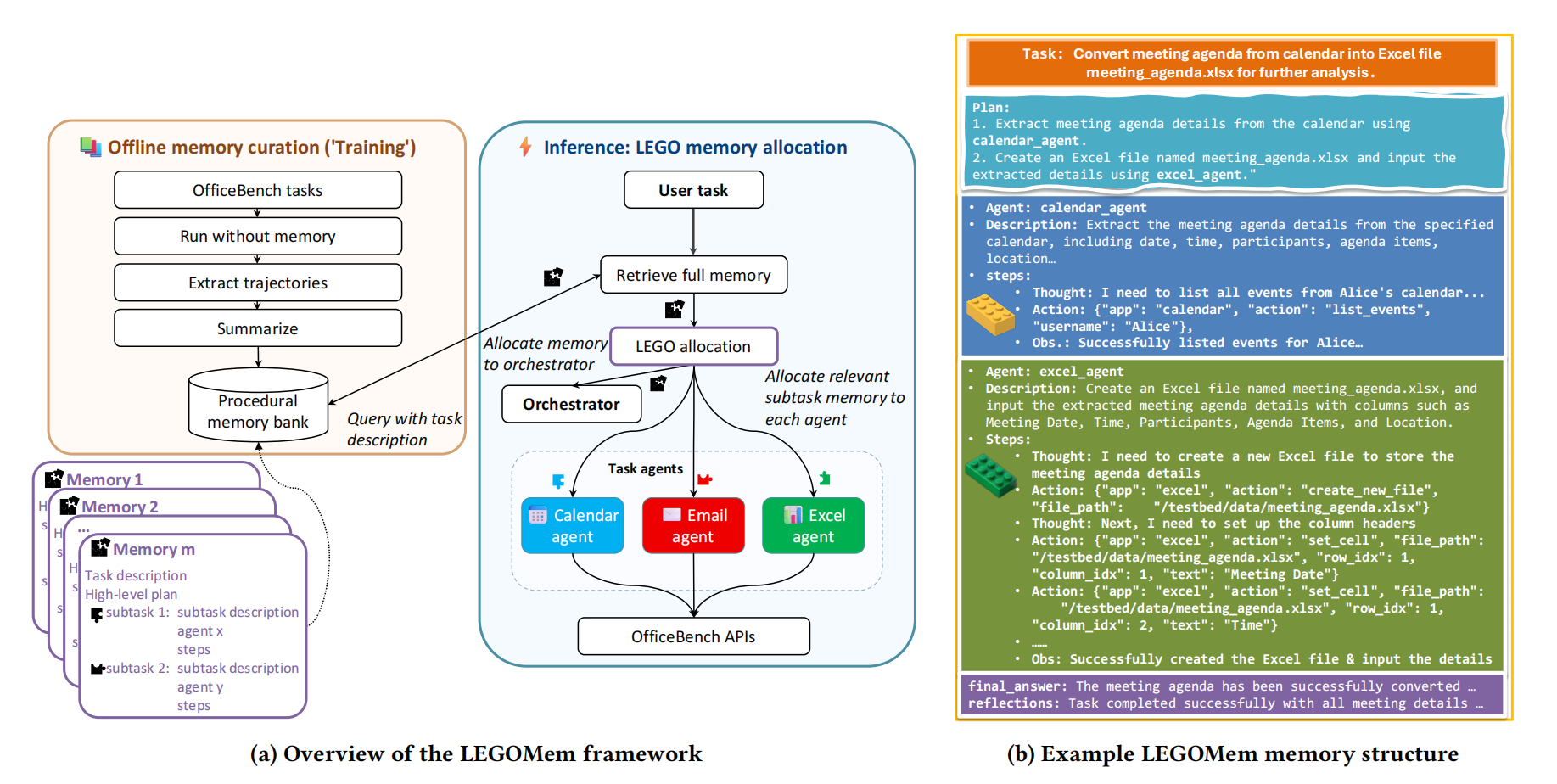
LEGOMem 的核心思想是:将成功的工作流轨迹像乐高积木一样,分解成标准化的、可重用的记忆模块,并在执行新任务时,将这些模块灵活地分配给系统中不同角色的智能体,以增强其规划和执行能力。
它的方法流程主要分为两个阶段:
阶段一:离线记忆构建
这个阶段的目标是从成功的任务执行轨迹中,提炼出结构化的记忆单元。
- 输入:成功完成的任务日志。日志记录了从协调器生成计划、分配任务,到各个任务智能体调用工具、获取观察结果的全过程。
- 记忆单元提取:使用LLM将原始日志转化为两种标准化的记忆单元:
- 完整任务记忆以及子任务记忆。前者包含任务的全局视角,为协调器配置,包含协调器指定的步骤计划、子任务执行序列、任务最终输出。任务关键事项总结等。后者聚焦于单个 Agent 的具体操作,包含具体执行步骤,环境返回的结果观察摘要等。
- 记忆存储与索引:
- 所有记忆单元被存入一个向量数据库(如 FAISS)。对于完整任务记忆,使用任务描述的嵌入向量进行索引;对于子任务记忆(在 Dynamic 和 QueryRewrite 变体中),会为每个类型的任务智能体建立独立的子记忆库,并使用子任务描述的嵌入向量进行索引。
阶段二:在线记忆增强推理
当有新任务输入时,系统会检索并分配相关记忆,引导智能体执行。
- 记忆检索与分配:
- 协调器会根据新任务的描述,从全局记忆库中检索最相似的 K 个完整任务记忆。这为协调器提供了“前人”是如何分解和解决类似任务的完整蓝图。任务智能体则根据其不同的变体,分配不同记忆:
- Vanilla LEGOMem: 直接从协调器检索到的完整任务记忆中,“拆出”对应的子任务记忆,静态地预分配给各任务智能体。
- LEGOMem-Dynamic: 不预分配。当协调器动态生成一个子任务并分配给某个智能体(如
A_i)时,系统实时地以该子任务描述为查询,在A_i的专属子记忆库中检索最相关的记忆。 - LEGOMem-QueryRewrite: 在任务开始前,先用一个LLM根据检索到的完整任务记忆,为新任务草拟一个步骤计划
π_draft,然后基于这个计划中的每个预期子任务描述,提前为各个智能体检索好相关子任务记忆。
- 协调器会根据新任务的描述,从全局记忆库中检索最相似的 K 个完整任务记忆。这为协调器提供了“前人”是如何分解和解决类似任务的完整蓝图。任务智能体则根据其不同的变体,分配不同记忆:
- 记忆增强的执行循环:
- 协调器利用获得的完整任务记忆进行初始规划和动态规划(包括重新规划)。
整个流程如下图所示:
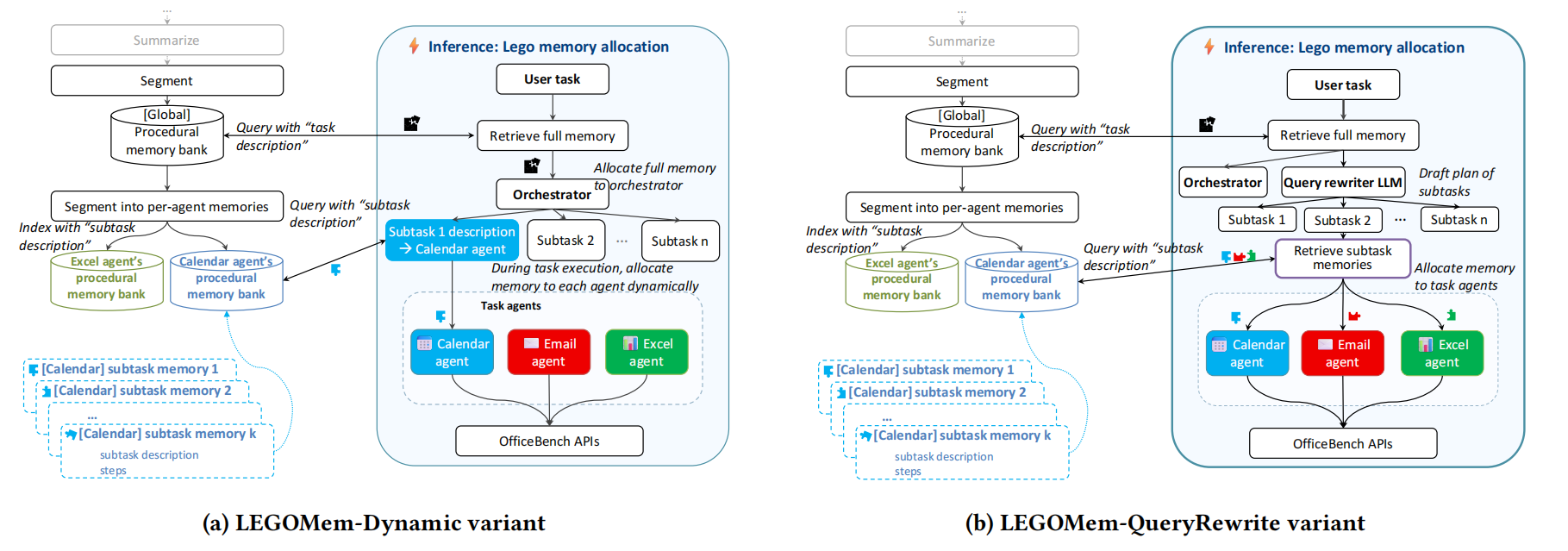
论文为了探究子任务检索粒度对多智能体系统的影响,提出了上文所述的对于任务智能体的三种变体。LEGOMem-Dynamic 和 LEGOMem-QueryRewrite 的工作流程如下图所示。
后续实验显示,当仅使用任务代理级记忆且任务代理采用小型语言模型时,LEGOMem-Dynamic 和 LEGOMem-QueryRewrite 的性能均优于标准 LEGOMem 。
Experiment & Results
- 数据集:OfficeBench,包含300个办公自动化任务,分为L1(单应用)、L2(双应用)、L3(多应用)三个难度级别。评估指标为任务成功率。
- 智能体配置:
- 分为三个配置:**(1) LLM 团队:全部使用 GPT-4o;(2) 混合团队:协调器用 GPT-4o,任务智能体用 GPT-4o-mini;(3) SLM 团队**:全部使用GPT-4o-mini
- 基线方法:No Memory、Synapse(全轨迹记忆)、AWM(子任务序列记忆)
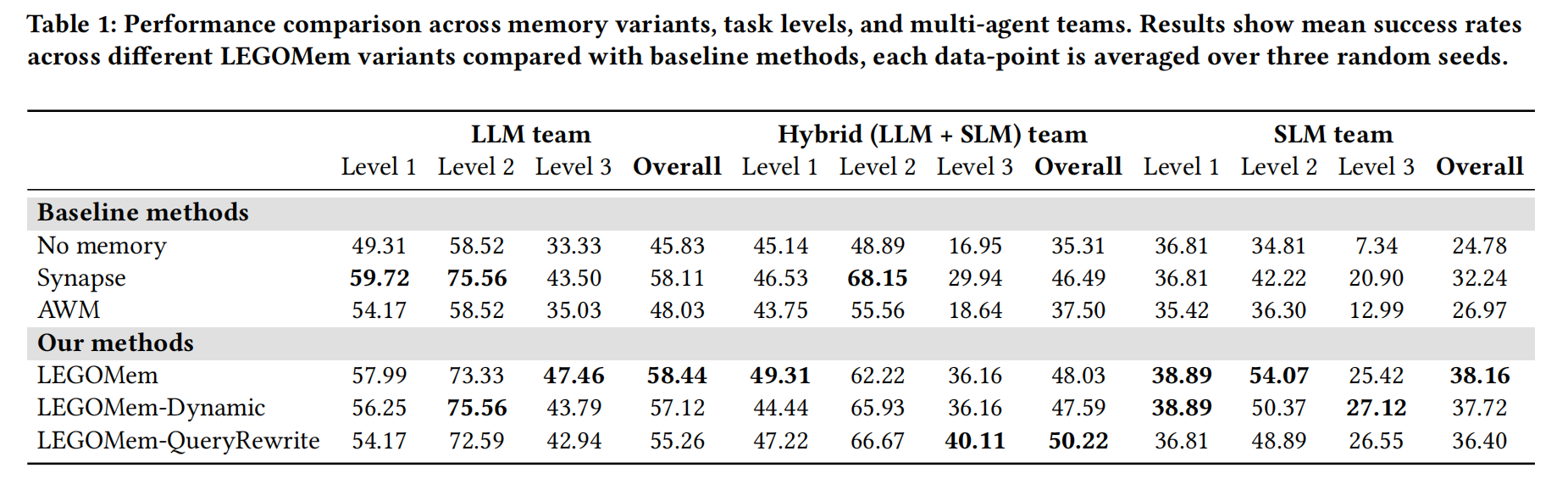
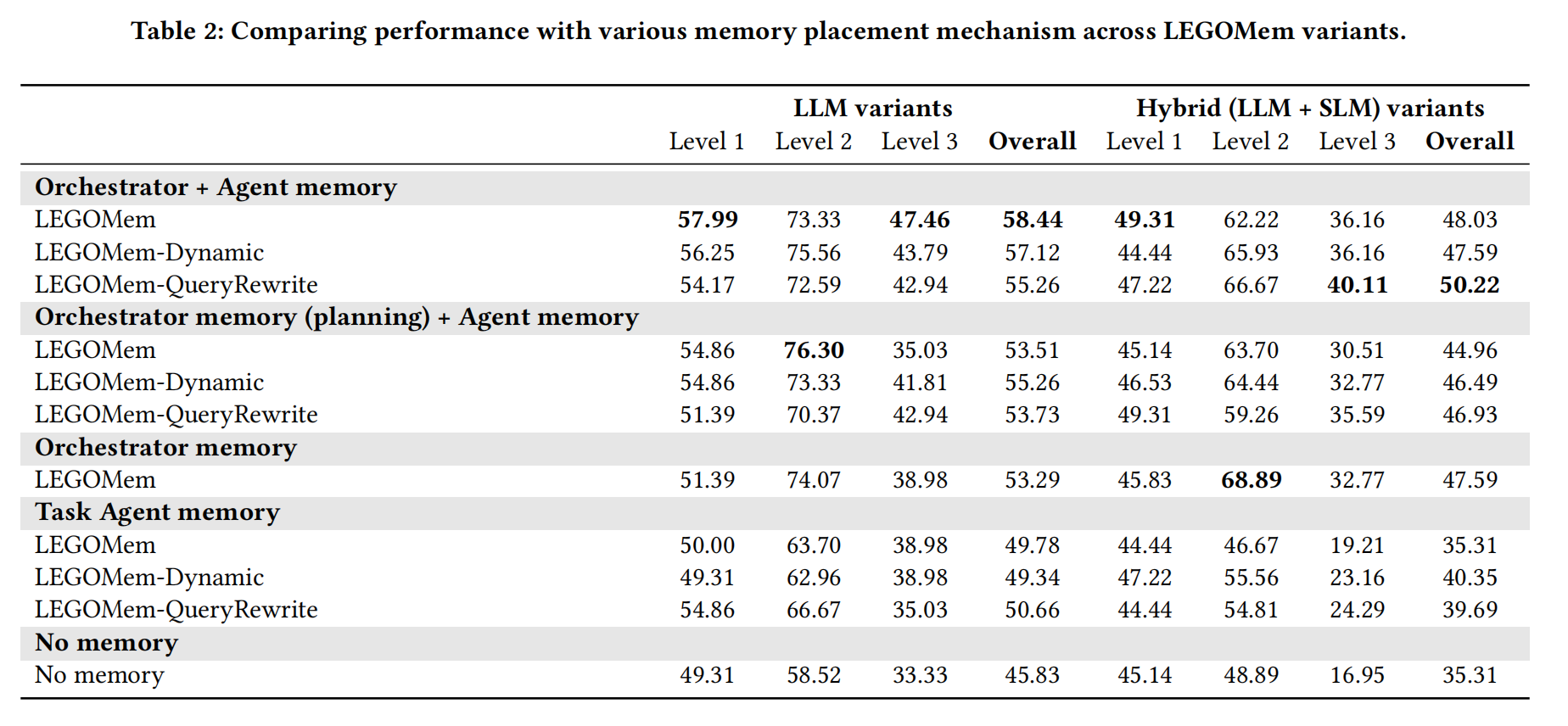
可以看到,所有 LEGOMem 变体均显著优于基线,平均提升约12-13%的成功率。- 轻量版 LEGOMem 表现最佳,说明模块化记忆结构本身已足够有效。并且使用 LEGOMem 后,SLM 团队甚至能超越无记忆的 LLM 团队。
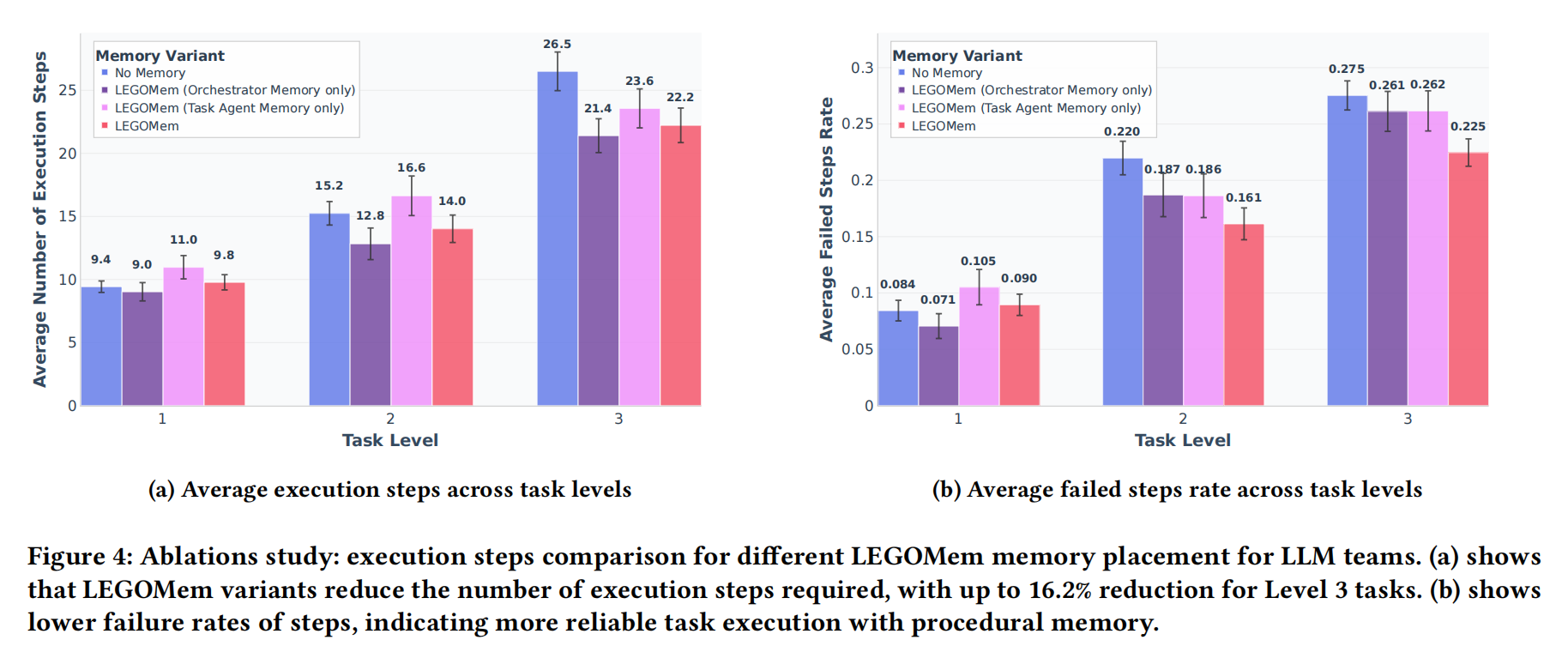
而在 LEGOMem 框架中,记忆究竟是为协调器更重要,还是为任务智能体更重要?论文在相同的任务(OfficeBench 基准)和相同的智能体团队(全 LLM 团队)下,只改变记忆的分配方式做了消融研究。评估指标:
- (a) 平均执行步骤数:完成一个任务需要多少个操作步骤(如工具调用)。步骤越少,代表效率越高。
- (b) 平均步骤失败率:智能体发出的操作指令中,出错(如调用错误工具、参数错误)的比例。失败率越低,代表执行可靠性越高。
可以看到,对于所有难度级别(L1-L3)的任务,任何形式的记忆都比没有记忆更高效(步骤更少)。仅协调器记忆 的表现远优于 仅任务智能体记忆,并且非常接近 完整LEGOMem 的效果。
因此,协调器记忆主导效率提升,它通过优化宏观规划来减少不必要的步骤;而任务智能体记忆在复杂场景下作为补充,通过提升局部执行精度来进一步优化效率。
与步骤数类似,任何形式的记忆都显著降低了步骤失败率,使执行过程更加稳定可靠。仅协调器记忆 在降低失败率方面效果非常显著,而 仅任务智能体记忆 的效果相对较弱。
因此,协调器记忆通过避免规划错误来提升可靠性,而任务智能体记忆通过避免操作错误来提升可靠性。两者结合,实现了最鲁棒的执行。
My Thoughts
首先这篇文章感觉实验论文就不太充分,主对比验证实验只做了一组。另外对比的基线方法也是只有简单的单 Agent 记忆构建方法,没有对比一些比较新的 Agent 记忆框架方法(比如 Mem0,、A-Mem 等)。数据集也不充分。
而且方法设计也很简单,感觉应该和 RAG 进行一下对比,看看是不是构建记忆阶段的记忆在真正发挥作用,不然又是一篇没啥意义的文章,还不如用静态 RAG 去做。就实验 Benchmark 来看,我感觉 RAG 没准效果更好,,
而且我感觉这篇文章根本不太涉及记忆更新啊,记忆库是在离线阶段一次性构建的,之后在整个实验过程中是静态的。它不具备在线更新或自我演进的能力。记忆库的规模和质量完全依赖于初始的“训练集”,推理过程不继续更新,感觉有点鸡肋。
还有一点就是,LEGOMEM 的记忆库完全由成功的任务轨迹构建。然而从失败中汲取教训同样至关重要,当前的框架无法避免重复掉入同一个陷阱,这点是之前谷歌那篇 ReasoningBank 探讨过的,我感觉比较有道理。
不过对于 Multi-Agent 的记忆设计来说,还是有一些学习价值的。首先就是多智能体系统里的 Agent 往往有不同的角色设计,感觉就很类似 MIRIX 那篇文章的思路(把记忆智能体拆成多个角色设计),所以在各种多智能体场景里,记忆 Agent 的设计又千变万化,很多换着玩的方法。
我大概想到一个比较简单的思路设计:在现有的 Multi-Agent 框架里,单独设计一个记忆智能体参与到多个智能体的交互之中,它相当于扮演“协调者”的角色,只不过是负责协调 memory 分配而不是任务的分配。那么这个 memory agent 就可以单门设计,通过 RL 或者别的一些方法都可以。
另外就是结合成功与失败,构建一个包含“正例”和“反例”的双重记忆库。在规划或执行时,系统不仅检索“应该怎么做”,也检索“需要避免什么”。协调器可以据此评估计划的风险,任务智能体可以避免常见的工具使用误区。
而且,多智能体系统的优点不是体现在智能体的协作联系吗?那是不是也可以设计一种方法,允许一个任务智能体在遇到困难时,主动向其他智能体(甚至是同类型智能体)的“个人经验库”发起查询?